2023-10-17 15:23:19 中华网
星环科技向量数据库Transwarp Hippo自发布已来,受到了众多用户的欢迎,帮助用户实现向量数据的存储、管理和检索,探索和实践大模型场景。在与用户不断地深入交流以及实践中,Hippo迎来了V1.1版本,一套系统即可支持向量与全文联合检索,提高文本数据的召回精度,从而提升大语言模型应用的准确率。同时,Hippo1.1新增余弦距离、批量数据导入导出、Explain与Profile支持、ARM架构支持等能力,大幅降低用户使用门槛和成本。
此外,Hippo社区版同样支持以上新特性,点击文末阅读原文或者访问星环科技官网,即可申请下载体验,开启大语言模型场景探索之旅。
一库搞定向量+全文联合检索,提升大模型准确率
在大语言模型应用中,向量数据库作为中间载体,可以有效地解决大模型在知识时效性低、输入能力有限、准确度低等问题,赋予大模型拥有“长期记忆”。因此,向量数据库的召回精度直接影响大模型输出结果的准确率。然而,在一些实践场景中,对于向量数据库本身而言,单一使用向量检索会产生召回准确率不高的问题:
* 对噪声和冗余信息敏感:若向量数据库中存在大量的噪声和冗余信息,则检索的准确率会降低;
* 对特征选择的依赖:在向量检索中,需要对数据进行特征提取和选择,若特征选择不当,则会影响检索的准确性;
* 对查询语义理解的局限性:当查询语义比较复杂或模糊时,向量检索无法准确理解用户的意图,导致准确率降低;
此外,像一些特殊情况,如所检索内容未构建特征或特征比重较小时,会导致准确率降低,甚至无召回结果。
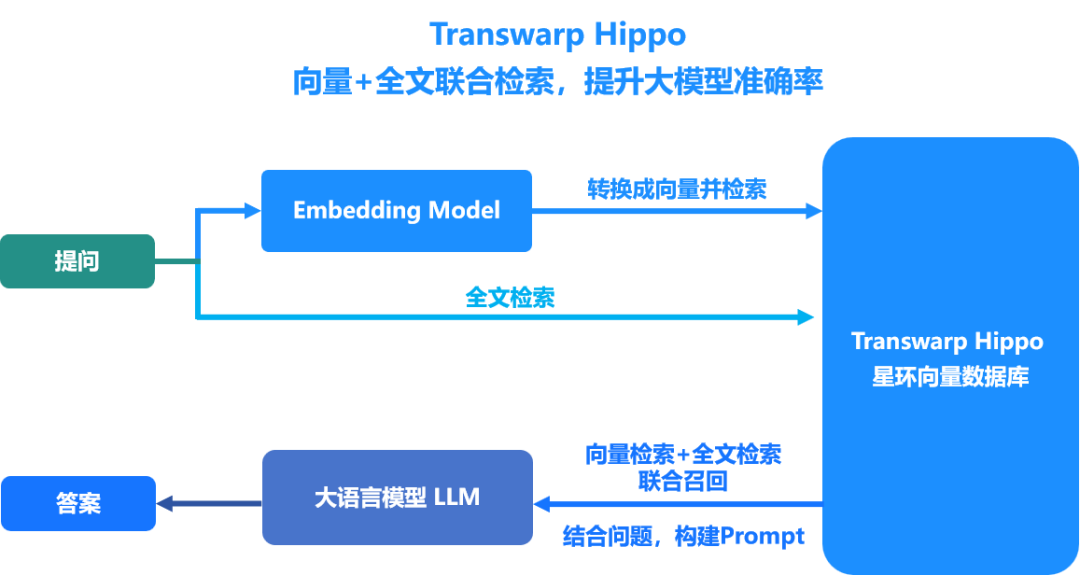
针对文本搜索场景,全文检索更适合做关键字匹配,可以避免检索内容低频的问题。而向量检索则能找出字面上不同但语义上相近的内容。通过将向量检索和全文检索的联合召回,可以降低漏检和误检的概率,能够实现比单独使用向量或全文检索更高的精度。
此外,向量数据与全文数据在存储、计算上有很大的差别,单一的数据库架构很难同时高效支持这两种场景。例如,对于公开数据集如ANN Benchmark,Elasticsearch的性能远落后于专业的向量数据库。
星环科技向量数据库Hippo底层使用自研的分布式数据管理系统TDDMS,能够支持向量数据和全文数据统一存储管理,一套数据库系统即可支持向量与全文数据联合检索召回,避免了部署多套系统带来的架构复杂、开发运维成本高等问题。同时,Hippo1.1提供兼容Elasticsearch协议的SDK支持,方便用户更便捷地使用向量数据库。
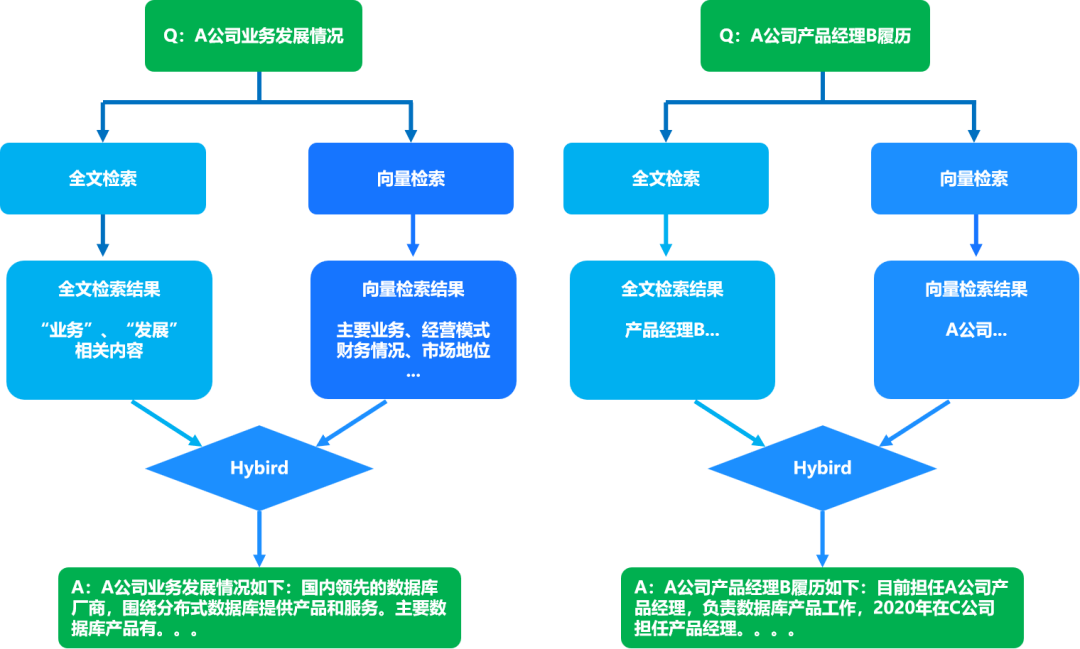
例如,当查询“A公司业务发展情况”时,通过向量检索可以检索出A公司“主要业务”、“经营模式”、“财务情况”、“市场地位”等信息,通过全文检索可以检索出知识库中和关键字“业务”、“发展”相关的结果作为补充,通过将两者检索的结果进行结合,可以使得大模型回答的结果更加丰满和准确。
当查询“A公司产品经理B的履历”时,若该产品经理B在知识库中出现的频率较低或未构建特征时,单一使用向量检索召回的结果可能主要是A公司介绍,而通过全文检索则会检索出产品经理B相关的内容,通过向量+全文的联合检索召回,使得大模型能够准确地给出答案。
多个新特性升级,帮助用户实现降本增效
1、余弦距离支持,简化业务逻辑
余弦距离在大模型领域有着广泛的应用。在过去,用户在将向量数据导入向量数据库之前,需要对数据库做L2归一化,并搭配内积距离间接实现余弦距离,这个过程较为复杂,需要用户手工操作,并要求有一定的技术基础。Hippo1.1新增原生的余弦距离支持,用户不再需要通过向量归一化计算 IP metrics 来使用余弦距离,大幅简化了业务逻辑,降低了用户使用门槛。
2、批量数据导入导出,加速数据流转
Hippo1.1新增基于csv格式的批量数据导入导出功能,方便用户进行数据流转。此外,用户还可以通过Python、Restful等API进行数据操作。
3、支持ARM架构,满足国产化需求
随着 ARM架构 CPU 的普及程度越来越高,Hippo1.1在支持X86架构的基础上,新增支持ARM架构,满足企业用户国产化需求。
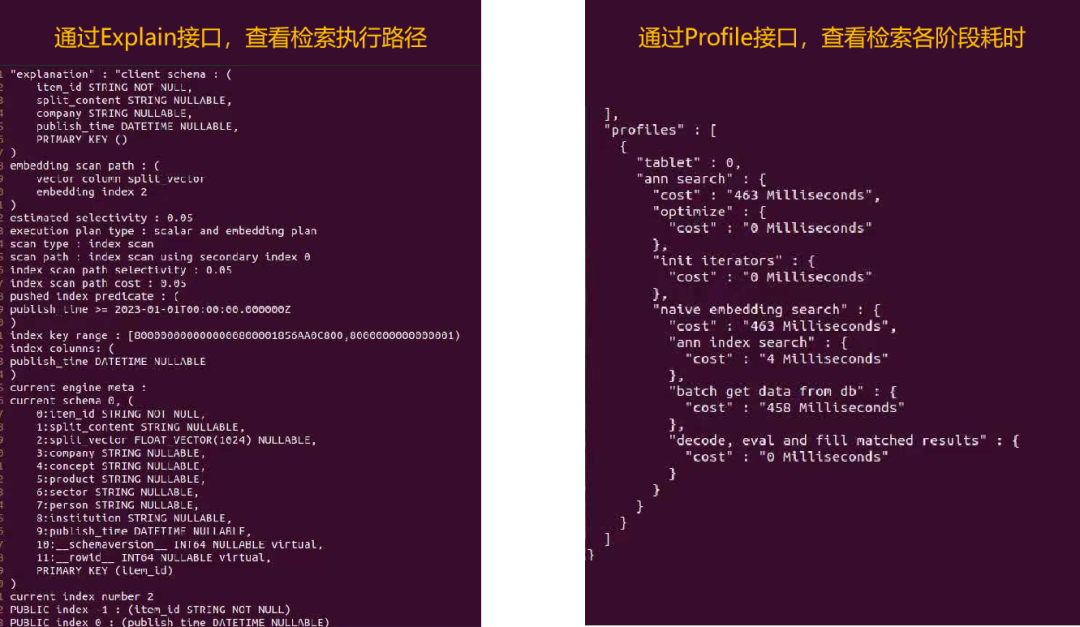
4、支持Explain与Profile,高效性能优化
当执行带过滤条件的向量检索时,Hippo会根据过滤条件预估过滤率,选择最优的搜索路径。通过Explain接口,用户可以准确地看到检索的具体执行路径,通过Profile接口,用户可以看到⼀次搜索中各阶段的细分耗时情况。基于这两点特性,用户可以更高效地进行数据库调试、问题排查和性能优化。