2025-11-24 19:24:41 机器之心
文章转载自《机器之心》
当俄罗斯首个 AI 人形机器人“艾多尔”伴着电影《洛奇》的主题曲蹒跚登场时,所有人都以为某个高光时刻即将来临。没想到,“帅不过三秒”——
向观众挥手后,它迅速失去平衡、倒地抽搐,被工作人员匆忙拖走。

近期翻车的机器人可不止这一家。9 月,特斯拉 Optimus 因反应迟缓被吐槽;1X 预售款的“惊艳演示”因系远程遥控,被舆论diss 到起飞。
业内人士对此并不意外。很多演示高度依赖人工操控,大量机器人连“站稳完成操作”都难,在工厂里“插个 dongle、贴个膜”,堪比“登月”。
英特尔在与数十家具身智能团队沟通过程中也发现,机器人“能跑会跳”和“能在产线干活”之间,还存在巨大鸿沟。
到底是什么原因阻挡它们踏入生产一线呢?
困在算力平台里的具身智能
11 月 19 日,重庆·2025 英特尔技术创新与产业生态大会的圆桌现场,训练数据、应用、“大脑/小脑分家”的架构问题都被摆上台面。但有一个答案被反复提及,算力平台正成为横在具身智能落地面前的最大门槛之一。
目前业内已量产、相对成熟的人形机器人,大多采用“大脑 + 小脑”的架构,所谓“慢系统 + 快系统”——
“大脑”负责深思熟虑,承担 LLM、VLM、CNN、CLIP、SAM 等对世界建模和理解的工作;
“小脑”负责“让身体动起来”,对反应速度极度敏感,包括 3D 定位导航、机械臂控制、步态控制等,控制频率动辄 500Hz~1000Hz。
过去机器人主要依赖传统运控,如今动作生成模型、多模态感知与大模型推理层层叠加,算力需求呈几何级增长。一位现场嘉宾提到,“我们用的很多其他行业厂家的芯片,达到 100 ~ 200 个 TOPS 的稀疏算力,但依然是不够用。”而这,还只是触及工业场景的冰山一角。
算力飙升之下,不少企业搞“拼凑”、搭“两套班子”。
比如,Intel 酷睿(12/13 代移动处理器)跑“大脑”,NVIDIA Jetson Orin 跑“小脑”,“两套班子”还要跨芯片通信、跨系统协同。
结果可想而知。想想“帅不过三秒”的“艾多尔”, 视觉指令传输存在延迟,机器人就会摔倒。目前困扰人形扰机器人的精度、效率问题,乃至端侧控制器的性能瓶颈,有一部分“归功于此”。
算力平台不仅是技术问题,更是落地的经济问题。
真正到后面小批量落地的人形机器人, ROI 肯定是我们第一个考虑的指标。有嘉宾直言。
制造业对 ROI 的考核最为严苛。
硬指标上,机器人不仅要能干活,“稳不稳定、安不安全、贵不贵、耗不耗电”都是老板们必须算清楚的账。
软指标上,为避免技术投资变成“一次性死资产”, 企业希望它既能迅速上线,又能随着工厂和产线变化灵活扩展或缩减。
显然,搞“两套班子”硬件堆叠,满足不了这些苛刻要求(开发成本、散热方案,功耗、价格、部署、可扩展性等)。
现场嘉宾认为,机器人要同时利用 CPU、GPU、NPU 多种异构算力,如何将这些异构算力高效整合到一块小体积、低功耗芯片里,还要让它们高度协同、被开发者轻松调用,是一道极大的挑战。
而且,随着具身智能加速演进,算力融合、扩展和利用效率,正在成为限制行业落地的关键瓶颈。
“解药”:以“单系统”达成大小脑的“融合”
需要“两套班子”才能完成的“大脑 + 小脑”任务,如今在一套“班子”里就能搞定。这正是英特尔给出的“大小脑融合”方案——
用一颗 SoC,把智能认知与实时控制统一到同一个架构中。
这颗 SoC,就是酷睿 Ultra 处理器。它在单一封装内集成了 CPU、英特尔锐炫™ GPU 和 NPU,并让三者协同工作,AI推理能力、高性能CPU计算与工业级实时控制,“一手”拿捏。
是不是很像重庆火锅的九宫格?每个 IP(CPU/GPU/NPU/I/O)就像格子里的一道菜,既能选“套餐”,也能随需求自由组合,全看机器人厂商的“口味”需求。
结果,原本必须上云的大模型推理,能直接在端侧运行,响应更快,隐私性也更高,关键还很经济。
酷睿 Ultra 在保持类似功耗的情况下实现了约 100 TOPS 的 AI 算力。英特尔公司副总裁兼英特尔边缘计算事业部的总经理Dan Rodriguez在大会Keynote上说到。用户不需要重构系统,只要升级 CPU,就能让原有产品具备 AI 能力。
先看看内置的GPU。
它拥有 77 TOPS 的 AI 算力,专门负责处理最重的视觉与大模型任务。这样的性能足以支撑 7B~13B 级别 VLM 的运行,对于物体识别、路径规划、分拣等任务已经游刃有余。
如果开发者需要更强的 AI 火力(更大的 LVM、VLA 等模型),可以通过 Intel Arc 独显进行扩展。
当算力需求冲上 千 TOPS 量级,例如大模型控制全身动作、执行多模态长链推理,英特尔认为应进一步结合外部“云脑”或边缘大脑来完成协同推理。
这种按需扩展的异构算力体系,成为具身智能顺利迈向复杂任务的关键基础。

NPU则负责轻负载常驻任务,如持续监听语音唤醒、动态物体检测等长期在线的 AI 功能,保证低功耗、零感延迟的体验。
CPU的价值被进一步放大。
得益于英特尔在传统机器人运控领域多年的积累,以及对底层指令和架构的深度优化,CPU 在跑传统视觉算法、运动规划时比过去更快、更稳。
比如,实时抖动小于 20 微秒,意味着机器人的平衡控制、复杂力控、手眼协调等对延迟极敏感的运控环节,现在都能跑在 CPU 上。
而且,CPU 内加入了专用 AI 加速指令,使其在视觉伺服等场景中,能够分担部分原本由 GPU 执行的 AI 推理与轨迹规划任务。这让算力调度更灵活、能效更优,也更符合机器人对功耗、实时性的苛刻要求。
Dan Rodriguez还提到,明年1月发布的 Panther Lake(18A 工艺)将进一步提升性能。图形性能最高提升 50%,同等性能下功耗降低 40%,AI 加速力提升至 180 TOPS,并支持扩展温度范围与工业级实时性,这意味着具身智能的应用边界将被进一步推开。
软件栈:三管齐下,落地按下快进
算力之外,英特尔同时把软件栈也配齐了。
从“机器人看什么、怎么学、怎么动”,一直到系统层面的调度、驱动、实时控制,英特尔提供了全栈套件,开发者不用“零帧”起步。
对于OXMs、ODMs、OEM等硬件制造商,英特尔准备的是整机级方案AI Edge Systems。操作系统、驱动、SDK、实时优化、BSP、EtherCAT 驱动,全都打包好。
比如一个已经打了 Preempt-RT 的 BSP,厂商不用再为实时性去改内核,把系统刷进去,机器人立刻具备“工业级心跳”。
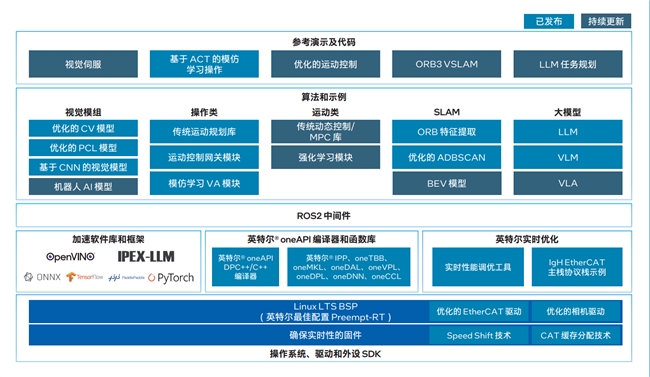
系统软件厂商处在中间层,需要把芯片的每一滴算力榨到极限,为上层应用提供最佳运行环境。英特尔给他们准备了Open Edge Software Toolkit,里面不仅有 AI 库和工具,更包含大量 OSV 级优化,确保在不同平台都能跑出稳定性能。
这里简单提几个英特尔构建自家 AI 生态的关键抓手。一个是oneAPI——一条贯通 CPU/GPU/NPU 的“算力高速路”。
开发者写一次代码,系统自动决定跑在哪颗单元上,CPU、GPU、NPU 甚至 FPGA,全自动调度与优化。
这能让存量设施(旧机器)和增量设施(新 AI 硬件)在同一套代码逻辑下协同工作,打破算力“孤岛”。要扩展算力?直接接上 Intel Arc 就行。
还有“黄金组合” OpenVINO + IPEX-LLM。
OpenVINO 负责 AI 推理加速,把 TensorFlow、PyTorch 等模型自动压缩、量化、瘦身,并转成最适合英特尔硬件执行的格式,推理在哪块算力单元上,也自动决定并负载均衡。IPEX-LLM 则让大模型在本地跑得更快。
两者组合,可以适配不同年代、不同规格的边缘设备,应对工业现场设备杂、环境复杂的现实挑战。
针对站在最上层的行业方案开发者(ISV/SI),英特尔提供了现成的行业模板AI Suites。抓取、导航等常见技能一键可用,需要加大模型就直接接 LLM、VLM、VLA,还自带参考 Demo,稍改即可落地,大幅缩短从“裸机”到“能干活的机器人”的周期。
破冰前行,开放致远
与动辄“全家桶、一锅端”的封闭路线不同,英特尔的“大小脑融合”选择的是一条更开放、更有弹性的技术路径:
同一套代码既能跑在 CPU/GPU/NPU/FPGA 上,也能在 Intel 与 Arm 平台间自由切换;
主流 AI 框架与模型全兼容,不锁库、不锁模型;
ROS2 与各类开源算法库也全部敞开支持。
从底层算力、网络,到软件栈、模型框架、应用框架,企业都可以按需自由组合。这意味着,他们不必推翻既有系统,也无需被某家供应商锁死,而是能够在自己的 IT/OT 基础之上、沿着现有行业生态继续演进,把数据和大模型真正变成生产力。
过去几个月里,英特尔已与国内数十家具身智能厂商深入合作,已有十余家进入验证或 POC 阶段。在技术与市场都充满不确定性的具身智能赛道里,这种开放自由的体系,正成为越来越多机器人企业愿意尝试的路线。
更多细节,可参考英特尔具身智能白皮书。