2023-10-12 18:47:04 IT168
在最近的杭州亚运会期间,一位智能“导游”吸引了很多的目光。它可不是一般人,它外观看上去像一辆小车,四个轮子在地面上快速灵活地移动。上面安装了机械臂,整体约一人高,机械臂上配有摄像头,以及语音和显示界面等交互设施,使其能够对周围环境和需要执行的任务进行识别与理解。
据悉,这台“导游”机器人系统是由北京大学计算机学院HMI团队研发,它结合了当前最前沿的AI技术——多模态大模型和具身智能,在亚运会期间,为视障人士提供引领和导航等帮助,并可解析视障人士的需求并完成相应任务,如帮助他们捡拾掉落的物品等,以其独特的方式,为亚运会的成功举办贡献了力量。

【图说】北京大学团队研发的多模态智能爱心助手在亚运会期间服务
「我们研发的这款多模态智能爱心助手,是基于团队自研的感知生成一体化多模态大模型,该系统能够精准地感知与理解视觉场景,生成准确丰富的语言描述,实现从人类复杂指令到具体行动的转化,并基于端云协作大小模型的协同高效微调,提升模型的泛化性,使其可以快速适应新场景。」北京大学计算机学院仉尚航研究员介绍。
「多模态大模型能够根据语言、2D、3D等多种输入模态,解析接收到的指令与周围环境,进行任务拆解并生成相应动作,完成服务任务。希望我们的研究可以用科技创新赋能弱势群体,让更多人感受未来科技的温暖,体验到亚运会的精彩。」
「多模态大模型+具身智能」系统首次落地大型体育赛事
「亚运会上有很多尖端科技的应用,很大程度上增强了运动员的比赛体验和观众的观赛体验。」北京大学学生庄棨宁表示:「但在深入研究和观察后,我们发现对于特定的观众群体,如少数民族和残疾人士,当前的技术并没有充分满足他们的需求。少数民族的观众可能面临语言障碍,而残疾人士可能需要更多的辅助工具或特别的服务,以便更好地享受比赛。」
为了解决这一问题,团队便萌生了研发一个专门服务残障人士观赛的AI系统的想法。「多模态大模型是我们课题组的重点研究方向,我们就在想有没有可能把多模态大模型和具身智能结合起来,为机器人赋予更加智能的大脑,使其可以将人类复杂需求转化为具体行动指令。」
「这样,我们的爱心助手可以更好地与用户互动,理解他们的需求,并快速做出有针对性的响应,更好地为亚运会弱势观众群体服务,也让更多人能够亲身体验到AI科技所带来的变革与温暖。」
在仉尚航研究员的指导和支持下,学生们迅速行动起来,并且追求了一种创新的路径,即设计「感知生成一体化的多模态大模型」,以实现对各种视觉场景的精准地感知与理解,并生成准确丰富的语言描述。

【图说】:仉尚航研究员(一排左四)和学生团队成员
同时,团队还将多模态大模型与具身智能相结合,由于机器人将面对不同场景,需要具备快速适应新场景的泛化能力,为此,团队设计了基于端云协作的大小模型协同高效微调,提升模型的泛化性,使其可以持续适应不同的场景。
在本次亚运会期间大显身手的多模态爱心助手,基于团队自研的感知生成一体化通用多模态大模型,其核心是一个参数量为7B/13B的多模态大模型,该模型集成了视觉基础模型的泛化感知能力和大语言模型的涌现能力。
例如,听到用户说「我渴了」之后,机器人能自动转身去拿过桌上的一瓶水送到用户手中。在这个看似简单的过程中,实际上涉及了一系列复杂的子任务:
. 机器人首先需要捕获有人说「我渴了」这个语音信号,然后通过语音识别技术将其转换为文字。
. 机器人需要理解「我渴了」这句话的含义,也就是说,理解说话者此时需要水。
. 然后,机器人需要知道在哪里能找到水,而这需要它对环境有一个良好的感知,利用计算机视觉技术,识别和定位瓶装水。
. 在确定了瓶装水的位置后,机器人需要规划一条到达那里的路径,这涉及到路径规划算法。
. 完成路径规划后,机器人需要控制自身的动作,移动到瓶装水的位置。
. 到达水瓶的位置后,机器人需要准确抓取瓶装水,这涉及视觉检测、机器人控制系统和抓取的相关技术。
. 抓取到水后,机器人需要规划返回的路径并控制自身的动作,将水送到说话者的手中。

每一个子任务都需要大量的研究和工程实践。不仅如此,机器人还需要能够处理在训练数据中未曾出现过的新情况,也就是说,模型需要具有强大的泛化能力,能够在新的、未知的环境中有效地工作。
为了提升机器人在开放环境下的持续性泛化能力,团队构建了一个端云协作的持续学习系统。这一系统的设计旨在兼顾终端计算的个性化、隐私保护和低通信成本等优势,同时也充分利用云端计算的大规模计算资源、大量标注数据以及卓越的泛化能力。通过高效的数据传输和合理的资源分配,实现了高度泛化的大小模型协同学习。
仉尚航研究员表示,「在终端设备上,我们部署了经过压缩的多模态模型,该模型在进行推理时能够同时进行不确定性估计。这一智能策略允许我们主动筛选出不确定性较高的样本,并将它们传送回云端。这些高不确定性的样本通常涉及新的数据分布,来自新场景、新环境或新事件等情况,这些都是在开放环境下需要特别重点识别和理解的情形。」
团队成员刘家铭同学也提及,「一旦这些高不确定性样本到达云端,我们利用未压缩的多模态大模型对它们进行深度分析和学习。通过知识蒸馏和高效微调等技术手段,我们将从这些难例样本中提取的知识传授给终端上的压缩模型。这个过程大幅度提高了压缩后的多模态模型的泛化能力,使机器人在开放世界中能够不断适应和理解各种场景。」
团队提出的端云协作持续学习系统,在设计和研发上充分发挥了云端和终端计算的优势,通过智能的样本筛选和知识传递,实现了机器人在开放环境中持续学习和适应的目标。这一创新的方法显著提升了多模态大模型的泛化性与高效性,为开放环境中的机器人系统赋予了更强的智能。
科技创新赋能弱势群体,让亚运会展现「AI的温度」
深度学习大模型技术的突破式发展带来了人工智能研究的革命性变化。预训练大模型,如 ChatGPT和 GPT-4,成为 AIGC 系统的核心。在基础设施支撑、顶层设计优化、下游需求旺盛三轮驱动下,人工智能大模型迎来了良好的发展契机。
不过,大模型研究仍处于研究的初期阶段,仍存在关键科学难题和卡脖子技术亟待解决,包括如何同时处理多种输入模态,如何进行大规模参数和高效训练,如何进行迁移学习和大模型微调,如何进行多模态和多任务学习,如何进行跨语言融合,如何进行人机协作等。
团队这次自研的感知生成一体化通用多模态大模型,已经展现出卓越的一体化处理能力,包括:视觉问答(VQA),能够对图像进行自然语言问答;Captioning,能够为图像生成描述性文本;行为决策与规划,具备基于图像和文本信息进行决策和规划的能力;以及目标检测,能够识别图像中的特定目标或特征。
「多模态大模型是我们组研究的核心,」北京大学计算机学院博士后王冠群介绍说:「目前也取得了一定的成果,除了这次自研的感知生成一体化通用多模态大模型、大小模型协同训练与部署,我们还关注多模态生成式大模型Agent设计、大模型记忆机制设计、面向多场景的智能医疗多模态大模型集群、通用大模型适配器等。」
据悉,团队研发的一体化大模型工具链(X-Accessory),旨在降低大模型使用门槛,促使各行业从业者能轻松调试大模型,在各自专有领域进化大模型的能力以灵活适配专有需求。「我们在硬件上搭载高算力一体机,同时提供直通云端调取云算力服务的选项,软件上搭载X-Accessory工具链,为用户提供灵活的大模型调试和应用环境。该工具链可用于训练和部署各类任务,包括但不限于金融知识问答、交通任务调度、医疗推荐等垂直领域的专有任务。」
基于多模态大模型,在北京大学计算机学院黄铁军教授及仉尚航研究员的指导下,团队还为本次亚运会研发了一款智能AI赛事解说系统。黄铁军教授提出了「脉冲连续摄影原理」,直接用每个像素的定额积分时间表达光强,相机速度取决于电路能够实现的最短信号读取时间,颠覆了持续近两个世纪的定时曝光成像原理,解决了传统相机不能兼顾超高速、高动态的问题,被中国电子学会鉴定认为是「超高速成像和机器视觉领域的重大原始创新,超高速成像技术达到国际领先水平」。有了高速脉冲相机,就能够同时实现超高速、高动态、全画幅连续成像。在此基础上,团队通过自研的 X-Accessory一体化大模型工具链,设计了多模态多语种视频解说系统,在亚运会期间用于乒乓球、跆拳道、跳水、体操等赛事。这个解说系统的特点在于,它不仅能够理解和分析正在进行的比赛,生成实时的解说内容,还可以根据观众的喜好提供个性化的解说服务,包括将解说内容翻译成多种语言,包括维吾尔语、阿拉伯语等,从而为全球各地的观众提供丰富的观赛体验。
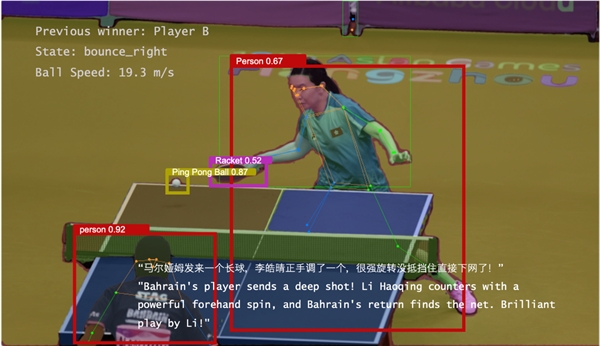
【图说】北京大学团队研发的智能赛事解说系统
在高速脉冲相机的加持下,能够清晰成像高速运动场景,捕捉比赛中的关键时刻,针对赛场画面进行多个语种的解说和报道,让更多的人了解亚运,特别是提升国内少数民族及国外多语种国家的赛事体验。
除此之外,团队还进行多模态生成式大模型Agent设计。当前,多数模型都是单模态的,无法有效地结合视觉、听觉和文本等多种模态信息。这种局限性在复杂的实际场景,如虚拟助手、机器人交互和智慧城市中,可能导致效果并不理想。「因此,我们开发了一种多模态生成式大模型Agent,将各种模态的优点结合起来,例如视觉的细节捕捉能力、听觉的时序特性和文本的结构化知识。这样的综合性设计将有助于推动生成式模型向更加实用和高效的方向发展,满足未来多种复杂应用场景的需求。」
在更复杂的应用场景,团队还研究过面向多场景的智能医疗多模态大模型集群。他们设计和实现了一组智能医疗多模态大模型集群,包括面向患者的个性化医疗知识问答多模态时序大模型、面向医生的临床影像报告生成多模态大模型和面向导诊场景的检索增强大语言模型,使大模型技术适配临床场景,满足患者-医生-医院多方诉求,解决行业痛点,推动大模型在医疗领域的落地应用。
在这个科技日新月异的时代,团队以其深厚的专业知识和创新精神,为亚运会提供了强大的科技支持,也为弱势群体带来了实质性的帮助。
未来,团队将继续秉持科技向善的原则,不断深化在多模态大模型的研究和实践,将AI技术的潜力最大限度地发挥出来,为解决社会问题、改善人们的生活提供更强大的支持。