2025-06-03 17:25:00 中华网
毕昇编译器以“全链路优化+生态兼容”为核心,打造开发者友好型工具链。在编译优化层面,前端支持异构混合编程编译,使能高性能Ascend C算子开发;中端通过昇腾亲和优化技术,提升算子性能20%以上;后端实现内存问题的分钟级定位。同时,开放AscendNPU IR接口,为开发者带来“快速开发”的编程体验,通过开源社区持续输出前沿技术能力,无感对接Triton、FlagTree等第三方编程框架,共建开放共赢的AI开发生态。
毕昇编译器全链路优化
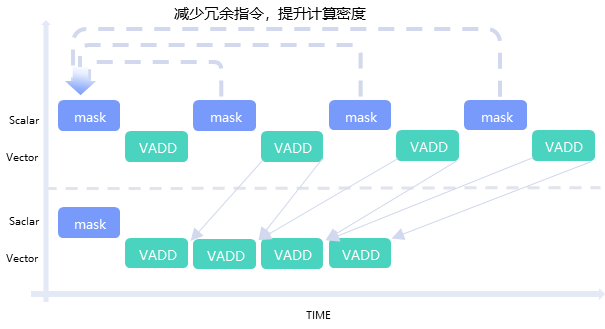
毕昇编译器作为昇腾算子开发的异构编译器,提供端到端的算子编译调优能力。在前端表达层,借助其混合编程编译能力,实现Host、Device异构编译,支持Ascend C高性能算子开发。在中端编译层,提供昇腾微架构亲和优化技术,自动完成指令调度与合并消减,有效减少冗余访存操作,使算子性能提升20%以上。后端生成过程中,不仅能自动优化寄存器分配,还可基于动态二进制插桩技术实现分钟级内存异常定位,并精准回溯至源码异常位置,从而大幅提升调试效率,缩短开发周期。
AscendNPU IR全面开放
AscendNPU IR是针对昇腾硬件设计的MLIR能力表达层,它会把硬件指令操作抽象成一系列高阶OP,方便与Linalg方言及其他三方框架进行对接。
1 AscendNPU IR具备的能力
1.1 昇腾硬件完备表达
面向昇腾硬件提供完备表达能力,抽象出硬件的计算、搬运、同步等高阶OP,通过毕昇编译器自动实现CV架构映射、片上内存管理、多处理单元流水并行,逐步完成高阶表达向细粒度OP,再到LLVM/机器码的翻译,释放硬件算力。
1.2 分层开放,灵活对接上层框架
昇腾采用自下而上的OP接口分层开放策略,提供从核内资源细粒度控制到核资源抽象的多层次接口。这种分层设计支持上层框架的灵活对接,赋能开发者基于昇腾硬件自主构建业务软件栈。
高阶抽象层可以分为搬运、计算和内存三大类操作,开发者只需关注Tile切分策略而无需了解底层硬件细节。同时,IR层提供了支持细粒度硬件控制的OP,可自主决策同步指令插入、片上内存地址控制以及乒乓流水等关键优化。这种灵活的分层开放机制,允许上层框架根据需求选择最合适的对接层级。
2 使用AscendNPU IR的价值
2.1 减少适配成本
MLIR已然成为现代AI编译器的关键一环,业界也在持续推动基于MLIR的编译技术演进。昇腾提供硬件MLIR层能力表达后,用户与企业能够快速将自身框架对接到AscendNPU IR,从而实现软件栈在昇腾平台的高效运行。
2.2 满足灵活定制需求
AscendNPU IR分层开放,开发者可以根据需求灵活选择合适的IR表达层级。既可以选择Tensor级别的OP实现快速适配,也可以选择细粒度指令集OP进行深度优化。此外,开发者还能根据业务需求实现算子融合,最终生成AscendNPU IR进行适配。
2.3 开放创新
AscendNPU IR为学术界及其他有创新需求的开发者提供了基于昇腾平台的创新研发机会。通过MLIR层级的抽象表达,开发者可直接基于AscendNPU IR开展前沿研究和技术创新,这不仅有助于丰富MLIR生态系统,更能推动编译技术的持续突破。
支持Triton算子开发,满足Python开发者使用习惯
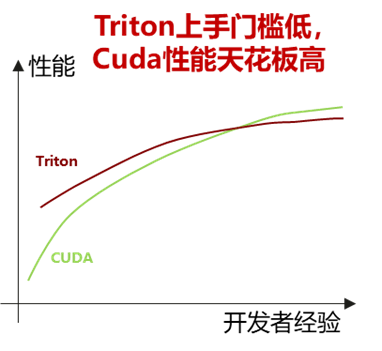
Triton是一个并行计算的编程语言与编译器,相比传统领域特定语言DSL等具有更强的灵活性,旨在平衡算子性能与开发效率。与CUDA相比,Triton的编程开发更为简洁,学习门槛低。即使是普通开发者,也能通过Triton相对容易地获得优异的计算性能。
昇腾在AscendNPU IR的基础上,新增了对社区MLIR的转换支持,以更好地适配Triton算子开发需求。如下图所示(红色虚线框标注部分为昇腾技术路线),其中的Linalg方言作为与硬件架构无关的中间表示层,因其在MLIR社区的广泛接受度和完善生态,已成为众多AI框架算子编译的通用入口。
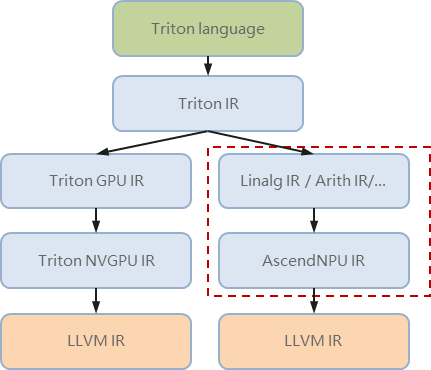
Triton IR转换成Linalg IR后,毕昇编译器将其作为输入,向下转换为昇腾专属MLIR方言,AscendNPU IR进行优化编译,最终生成高效的算子二进制。
未来的演进与思考
从高门槛的开发工具,到如今面向开发者开放的现代化AI编程体系,昇腾正在以实际行动推动AI硬件生态的全面升级。AscendNPU IR的开放与Triton对接方案的正式发布,也是昇腾向开发者发出生态共建的诚挚邀约。未来,昇腾将通过开源社区持续输出技术能力,推动昇腾与全球AI开发生态的深度融合。
更多内容,可参考昇腾社区代码仓:
AscendNPU IR:https://gitee.com/ascend/ascendnpu-ir
Triton Ascend:https://gitee.com/ascend/triton-ascend