2025-04-11 11:17:48 中华网
美东时间3月20日,OpenAI举行了一场重磅的技术直播,发布了三款全新语音模型:语音转文本模型GPT-4o Transcribe和GPT-4o MiniTranscribe,以及文本转语音模型GPT-4o MiniTTS。OpenAI声称,这些模型符合其更广泛的“AI智能体(AI Agent)”的愿景:构建能够代表用户独立完成任务的自动化系统。
在这次OpenAI掀起的语音智能体浪潮中,其最新发布的gpt-4o-transcribe模型作为当前性能最好的语音识别理解模型,将极大推进包括客服,个人助理,具身等多个智能体的市场规模。GPT-4o Transcribe再次刷新了行业标杆,同时行业的目光再次聚焦于一个核心指标:“识别错误率(WER)”。通过强化学习与海量高质量语音数据的深度融合,这款全新模型在LibriSpeech、FLEURS等多项权威基准测试中WER有效降低,并刷新了多语言WER记录,尤其在嘈杂环境、多语速场景和非标准口音下的表现显著优于现有方案。
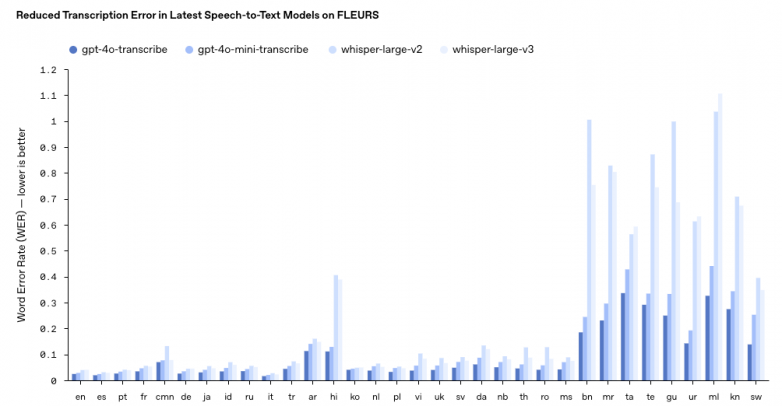
图. OpenAI几种大模型单词错误率(引用来源OpenAI)
据OpenAI披露,GPT-4o Transcribe的突破性表现源于两大关键技术:一方面,通过自博弈强化学习框架,模型在模拟真实交互中不断优化对语音细微特征的捕捉能力;另一方面,,基于超大规模、多语言、高保真的音频数据集进行“中期训练”。覆盖超过50种语言、数千小时的真实对话与复杂声学场景(如背景噪音、语速突变、口音混合等),使模型可以更好地捕捉语音的细微差别,减少误认,并提高转录可靠性。这种“算法+数据”的双轮驱动,将语音转写的可靠性提升至新高度。这一技术提升,预示着大模型的训练阶段,从基础的预训练阶段,走向了更为复杂多样化的中训练阶段。
这一突破不仅印证了语音技术向多模态、强鲁棒性演进的趋势,更揭示了底层数据的核心价值:高质量、多样化、多语言的语音数据,是构建下一代语音智能体的基石。
无限趋近于零错误率,是未来人类在大模型性能优化方面的不懈追求,永不止步。OpenAI不断更新的模型性能,印证了:语音智能的进化,本质是数据质量的进化。无论是强化学习所需的动态交互样本,还是覆盖全球语言与口音的多样性语料,亦或是严格对齐的语音-文本标注,都要求数据集具备多维度、高精度、强泛化的特性。
值此技术跃迁之际,晴数智慧正式推出了非常适合用于语音大模型/端到端模型“中训练阶段”的「多语种高质量口语式语音数据集」(Multilingual high-quality Spoken Language Speech dataset)。该旨在为全球开发者与企业提供语音模型创新的“新燃料”。
多语种高质量口语式语音数据集核心价值:
1、覆盖中文、英语、西班牙语、葡萄牙语、法语、日语、韩语等30+语种,每个语种上万小时;
2、场景类型丰富,人数众多,内容表达多样,使模学习到优秀的泛化能力;
3、主要为口语式自然风格训练数据,让模型学会最自然的交流方式;
4、音字匹配的高质量数据,字准率达98%+以上;
5、句子完整度高,利于准确分析句意;
6、标点合理,有助于模型学习人类的自然停顿和韵律特点。
该数据集可以极大程度帮助扩展语音大模型/端到端模型的多样性、口语式、泛化性,帮助模型提升如下性能:
1、语言理解能力
(1)口音与风格适应:涵盖多语言、多口音以及不同说话风格的数据,可让模型适应各种语音特征,准确理解不同地域、不同文化背景下用户的语言表达,提升模型的泛化能力。
(2)上下文理解:通过对每位说话者语音的独立分析以及分类标注,更好地把握语义。
(3)实时交互理解:数据完整保留了口语过程中自然的停顿、重音等动态过程,使模型能够理解和适应真实场景下的实时交互模式,不再局限于僵化的一问一答模式。
2、语音生成能力
(1)自然度提升:基于真实场景下自然流畅的口语数据训练,模型生成的语音在语调、语速、停顿等方面会更接近真人,让用户在与模型交互时感觉更加自然舒适。
(2)个性化生成:通过学习不同说话人的语音特点,模型可以根据用户的身份、偏好等因素生成更加个性化的语音回应,满足不同用户的需求。
3、跨语言交互能力:多语言的数据集为模型提供了丰富的跨语言信息,有助于模型学习不同语言之间的转换和映射关系,从而实现语音翻译等跨语言交互功能,促进不同语言用户之间的交流。
该数据集所具备的“多样化、高质量、口语式”数据特质,将助力开发者训练更具自然性与准确性的模型,推动语音智能在全球化场景中落地——无论是打破语言壁垒,还是赋予AI更自然的表达,高质量数据的支撑,终将成为智能语音时代的关键引擎。
数据定义边界,语音连接世界——让我们以开放、精准、多维的语音数据,共同开启智能交互的新篇章。