2024-05-23 14:29:05 中金在线
随着上周字节跳动高调入局大模型战场,并带领豆包大模型击穿市场底价开始,到最近,先是阿里云宣布了通义千问GPT-4级主力模型Qwen-Long API输入价格从0.02元/千tokens降至0.0005元/千tokens,直降97%。紧跟着,百度智能云也跳出来表示,文心大模型两大主力模型全面免费。

然后就是科大讯飞在近日也宣布,讯飞星火API能力正式免费开放。其中,讯飞星火Lite API永久免费开放,讯飞星火顶配版(Spark3.5 Max)API价格低至0.21/万Tokens。
简单计算一下,当前百度文心一言ERNIE-4. 0和阿里通义千问Qwen-Max 的定价为1.2元/万Tokens,而讯飞星火定价已不足其五分之一。
当然这还没完,再加上更早之前的OpenAI宣布其最新模型GPT-4o的价格下调50%,以及Kimi、智谱等大模型近期在变现和定价上的新动作,一场大模型界的“618”大促似乎正在成形。
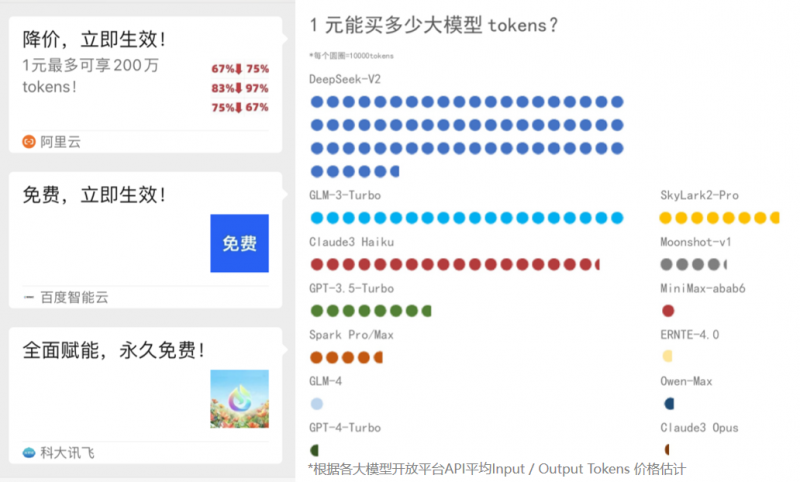
但越是如此,也越发地令人疑惑,为什么如此多的大模型玩家们都要在此时宣布降价?降价是为了打价格战吗?大模型降价对于市场和行业来说又意味着什么呢?
降价并非打价格战,而是做大“市场蛋糕”?
从降价到免费,乍一看确实有点价格战的意味。
但再仔细观察一下就知道,真相恐怕并非如此。
首先,不可否认的是,此次宣布免费的API已经好过了很多开源的API。
但是,因为各家大模型侧重的行业领域,以及企业优势经验不同。再加上现在大模型的发展已经超越了传统的摩尔定律,更新迭代的速度非常快,性能翻倍的时间周期在不断缩短。所以这就使得市场很容易存在不同品牌企业、不同分层阶段的大模型产品。
那么在这种缺乏统一标准的情况下,只有最新、最好、最稳定的技术才能收费,自然就逐渐成了现在大模型行业的一个隐约共识。因此,免费并不能算是科大讯飞要打价格战的信号。
至于说降价为什么也可能不是在打价格战?
原因有两点:一是当前科大讯飞、字节(豆包)们的降价不是赔本赚吆喝,而是通过技术和模型结构的优化升级换来的,有点像技术进步的必然。
大模型的成本下降不仅依赖于硬件成本的降低,还涉及到算法优化和模型训练、部署技术的进步。例如,通过剪枝、量化和知识蒸馏等技术,可以显著降低计算复杂度和资源消耗。
在这方面,科大讯飞对于大模型的能力和成本优化则更加全面,旗下的讯飞星火大模型是通过技术手段去平衡模型能力与算力成本,从而在保证模型能力性能不变或者损失很小的情况下,可以将模型尽可能做小。让大模型像一根如意金箍棒一样,可大可小,满足不同应用场景下的需要。
不过在此之前,科大讯飞需要先跨过算力这道拦路虎。此前曾有业内人士表示,现在国产大模型行业训练和推理算力的合计成本占大模型总成本的40%以上。这既包含了企业定制、微调大模型的算力成本,还包含国产大模型算力底座的自主可控。
为此,科大讯飞联合华为推出了首个全国产算力的超大规模算力平台“飞星一号”,讯飞星火V3.5也就成了首个基于全国产算力训练的大模型产品。同时,星火开源大模型也基于飞星一号实现了全栈国产适配优化,训练效率达A100的90%。这也意味着,科大讯飞为企业客户提供了另外一种成本更低的、“大模型+算力”的国产选择。
随后在算法优化和模型训练、部署技术方面,以最近大热的长文本能力为例,科大讯飞对讯飞星火V3.5进行了重要的模型剪枝和蒸馏,从而推出了业界性能最优的130亿参数的大模型,在效果损失仅3%以内的情况下,使得星火在文档上传解析处理、知识问答的首响时间以及文字生成方面都获得了降本增效般地全面提升。
二是现在业界普遍认为,随着大模型性能逐渐提升,AI应用创新正在进入商业化探索期,但推理成本过高却成了制约大模型规模化应用的关键因素。所以降价可能是为了让更多人更多行业先用起来、先跑起来大模型,从而为后续的商业化应用积累市场群体基础。
毫不夸张地说,现在即便有不少大企业和中小企业对AI大模型感兴趣,但是真当落地应用的时候,其实际上也是很难能做出最后选型决策的。
一方面,因为现在的大模型产品可谓是花样百出,企业难以做出最优解;另一方面,对大企业来说各个业务和部门繁多且交叉复杂,使用大模型的试错成本很大;至于中小企业则是由于成本限制和缺乏专业数据处理的经验,容易导致AI模型的实际应用效果很难与自身业务快速适配,企业存在“赔了夫人又折兵”的创新担忧。
在这方面,字节方面的高管此前曾粗略地算过一笔账,企业要想用AI做一项创新,至少要消耗100亿token,如果按照大模型之前的售价,平均需要花费80万元……
那么这就很明显,现在大模型想要落地的前提,就是价格要让大家都用得起,企业的使用大模型的试错成本降到极致,这才能快速做大市场蛋糕,共同推进商业化的落地……
低价大模型的意义是什么?
其实对于现在科大讯飞等大模型们的降价,从第三方视角来看也颇有意思。
一是和过去互联网企业的发展路子相似,大模型也是用户用的多了,收集训练的数据也就更加充分,大模型的体验也就更好。
所以对于此次的降价,有业内人士就直言道:好的技术一定是在大规模应用,不断打磨的情况下形成的。只有在真实场景中落地,用的人越多,调用量越大,才能让模型越来越好。
二是可以提前抢占更多“试用”群体资源,增加后续的商业转化比例。
其实这个很好理解,虽然从2023年开始,全球范围都掀起了以大模型为代表的生成式AI浪潮,但无论从技术革新还是价值普及的角度看,国产大模型并没有给生产生活方式带来更多质的改变,也没有实现用户的全面破圈普及。

在这种情况下,如果大模型开发者和应用者们继续再卷大模型参数,或许依然有用,但在商业化方面还就远远不够,其需要提前开始为抢夺市场和消费用户们铺路了。
直白点讲就是,品牌大模型要主动帮助用户降低试错成本、降低企业使用AI服务的门槛。只有价格越低,也就越能吸引来更多的“试用”群体,然后让用户在体验试用中提前做出品牌大模型选择,从而为后续的商业转化铺路造桥……
所以从这个角度看,现在品牌大模型集体降价,既可以看做是与行业共同做大蛋糕,也可以是通过用户对市场进行提前筛选和优胜劣汰,同时还能是让品牌企业从用户反馈中查缺补漏,然后更精准快速地优化升级大模型产品和服务……
至于第三点,多数企业之所以愿意拥抱大模型和AI时代,无非就是希望能够实现经营成本的降低或效率的提升,在激烈的市场竞争中借助大模型打造出差异化优势,从而提升自身的企业竞争力。
那么在此背景下的大模型集体降价,往小了说是帮助企业实现价值突破,但往大了说也未尝不能看做是,以科大讯飞为代表的大模型玩家们推动中国科技进步的一小步,同时也是赋能全产业链向AI智能化转型,促进实体经济复苏的重要一大步,这背后藏是科技巨头企业们的社会担当与责任。
总之,作为大模型商业化的元年,以科大讯飞为代表的一众国产大模型玩家们正在以更快速的技术迭代与更灵活的落地应用不断推动生产力的变革。
哪怕在这一前进的过程中仍布满了各种各样的挫折和弯路,但现在各大模型厂商已经纷纷亮剑,所以接下来很长一段时间内,我们或许将能看到更多的智能化应用出现在工作与生活之中,从而一步步拉开AI变革的时代序幕……