2023-04-03 15:09:02 CSDN
导语
数据分析引擎是数字经济时代的新动能,但很多数据分析引擎无法满足实时处理大规模数据的性能要求。柏睿数据从“根技术”自主研发的全内存分布式数据库RapidsDB,通过内存存储、MPP并行计算、动态查询优化和即时编译等查询性能优化技术,为企业提供全球领先的数据处理和分析能力,构建高性能、安全合规、自动化的数据洞察数字化平台,灵活满足企业多元交付场景的实时数据分析与海量数据高效管理需求。柏睿数据RapidsDB研发负责人丁若冰将详解柏睿数据RapidsDB查询性能优化之道。
一、背景
作为国家重大发展战略,数字经济越是发展,数据的价值越为突出。如何充分挖掘数据价值成为核心任务之一,其中在数据处理这一“价值变现”的关键环节,必然要解决如何处理超大规模量级的数据,以及如何将大规模数据进行实时高效分析和应用等问题,此时则需要强大的数据分析引擎来支撑。可以说,数据分析引擎将是数字经济时代的新动能,并助力实体经济高质量发展。
数字化转型中的企业要成为优秀的数字化组织,同样需要具备实时高效、灵活易用、可扩展的数据分析基础设施,从而充分发挥数据价值,形成业务数据化和数据业务化的驱动闭环,更好地实现智能商业决策、生产经营优化及产品和服务创新。但很多数据分析引擎因受限于低效的磁盘I/O、不合理的执行计划,单机的处理能力上限等因素,无法满足企业实际业务场景中实时处理和分析大规模数据的性能要求。
为助力数字经济高质量发展、加速企业数字化转型,柏睿数据打造具有完全自主知识产权的全内存分布式数据库RapidsDB,做到了极致的数据处理和分析性能。通过内存存储、MPP并行计算、动态查询优化和即时编译等查询性能优化技术,突破了数据库诸多性能瓶颈,构建性能全球领先、安全合规、自动化的数据洞察数字化平台,灵活满足多元交付场景的实时数据分析与海量数据高效管理需求。
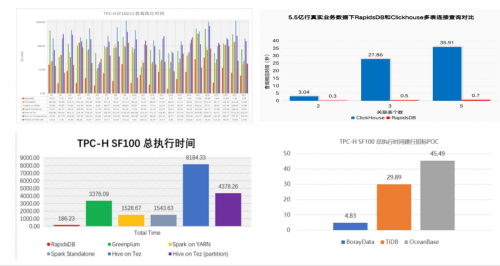
柏睿数据RapidsDB与常见数据分析引擎性能对比
如上图,在某国有大型银行招标测试的TPC-H SF100测试上,柏睿数据RapidsDB在各场景的性能测试中,整体性能较诸多常见数据分析引擎大幅领先。从总执行时间上可看出,柏睿数据RapidsDB在100G的TPC-H数据集上查询性能是常见查询引擎的至少8倍。
二、技术原理与实践
1、RapidsDB技术架构
RapidsDB是柏睿数据新一代数据智能产品体系中的核心算力引擎,基于全内存分布式架构,全面对标Spark计算引擎,帮助企业建立大规模实时数据高效处理与分析平台。
RapidsDB技术架构由管理工具模块、接口模块、分布式计算与存储集群模块和数据联邦模块组成。

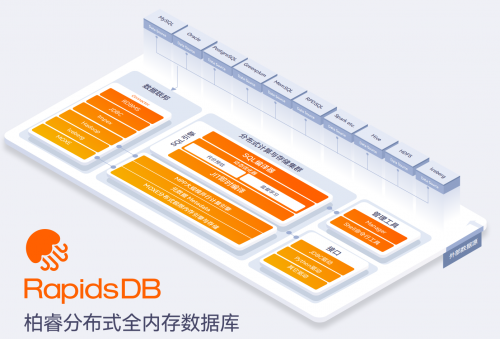
RapidsDB架构图
•管理工具模块提供管理支持。用户可以使用RapidsDB的Manager工具,简单便捷地完成RapidDB的安装、部署、监控和运维;同时可以使用RapidsShell工具,在命令行上对RapidDB进行操作和使用。
•接口模块提供对外接入的入口。提供Java、Python等主流语言的驱动程序,用户可以使用多种编程语言,通过标准的驱动API完成对数据库的接入操作。
•分布式计算与存储集群提供查询计算和数据存储。用户的操作请求通过驱动传递到存储与计算集群,存储与计算集群完成对用户请求的高性能的解析、优化、执行和响应。
•数据联邦模块提供联邦查询服务。联邦模块通过可插拔的连接器接入20+异构数据源,灵活实现跨数据源的查询、分析、聚合等操作。
柏睿数据RapidsDB采取的查询性能优化手段具体如下。
2、内存存储架构,提升I/O速度
RapidsDB采用内存存储架构,能够做到纳秒级的读写性能,远超微秒级磁盘读写性能几十万倍。RapidsDB存储引擎Moxe的数据以堆外内存来存储,一方面可以利用内存本身的高效读写性能,另一方面堆外内存无需垃圾回收,可以减少垃圾回收器的停顿时间,从而提升程序性能。
3、MPP引擎,横向扩展计算性能
RapidsDB使用MPP架构(大规模并行处理架构),在计算时可以将一个查询任务拆分成多个并行执行的小任务,并分发给MPP集群中的多个节点来执行,从而有效提升任务、算子执行的并行度,提高RapidsDB的查询性能。
4、动态查询优化技术,智能优化查询计划
动态查询优化技术是柏睿数据独立自主研发的技术,已获美国授权专利。它使用一种叫做代价预估的机制,对于每一个执行计划、执行子计划、算子给出基数假设,通过在执行中最终基数的反馈来动态地调整最初的基数,辅以机器学习的方法来提升基数估算的准确度。这些评估调整的基数用于帮助 RapidsDB确定操作符的执行顺序、确定查询中JOIN的顺序、指导RapidsDB拆分任务、预计算及缓存数据。
随着RapidsDB运行的越久,对执行计划、执行子计划、算子的基数假设就会越精准,那么基于基数所做决策的效率就会越高。
5、即时编译,特殊代码生成提速查询执行
RapidsDB使用Lambda Flow与内存存储引擎相结合,在查询执行阶段通过即时编译提高执行效率。
RapidsDB的Lambda Flow利用即时编译技术(JIT Compiler),在查询时将频繁执行的方法进行特殊代码生成,再编译为机器代码,提升执行效率。例如,针对WHERE条件判断、聚合运算等场景,RapidsDB计算引擎实时地将表达式的路径编译为具体代码执行,在原过程中产生的大量不必要的调用和分支跳转则都会被优化掉。
MOXE存储层也做了相同的优化。针对特定的表结构,MOXE定制了读取和解析元组的代码。如在解析元组的流程中,根据表结构动态生成的代码,无需做数据类型的重复判断,只需按照顺序解析数据。另外,在获取部分列时,实现直接根据对应偏移量提取数据,跳过不需要提取的列,从而降低计算及I/O开销。随着处理的数据量增加,节省的计算及I/O量是惊人的。
6、联邦查询,零数据迁移
RapidsDB通过可插拔的联邦连接器来完成对20余种异构数据源的统一访问支持。联邦连接器内置Oracle、MySQL、PostgreSQL、Hive、Kafka等连接器,能够直接完成对相应数据源的实时接入、查询、分析功能,无需数据迁移,大大提高了数据处理和分析效能。
此外联邦连接器还支持跨数据源的连接查询,能够透明融合企业跨部门数据源的数据查询分析,突破数据共享瓶颈,实现多方数据安全高效流通。
三、应用实践和收益
随着企业上云数字化转型进程的加速,中国移动某专业公司持续助力云计算产业发展和行业数字化转型。与此同时,该公司的业务数据也迎来指数级增长,总存储量高达百倍TB级别,同时业务场景也越来越复杂,由此对经营分析系统的数据库查询分析性能提出了更高要求。经过科学评估和测试,最终选择柏睿数据RapidsDB来替代原有基于磁盘架构的数据库MySQL。
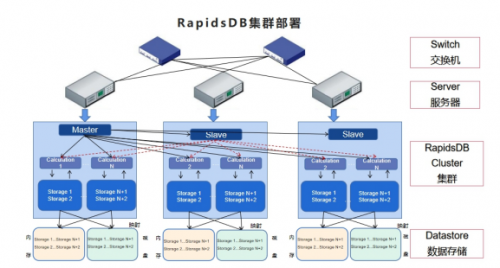
柏睿数据RapidsDB集群部署
该公司在其经营分析系统上部署了一主两从的三节点柏睿数据RapidsDB集群,基于RapidsDB无磁盘IO、高并发、高可扩展性、低延时以及高速存取等核心优势,满足了数据查询性能提升、数据架构精简和数据融合等实际业务场景需求,实现TB级数据秒级响应,数据查询分析效率整体提升约200倍,同时降低了数据库开发、运维和更换建设成本,助力该公司切实高效地激活数据要素潜能,加速全方位云化转型。

柏睿数据RapidsDB与原有数据库的查询性能对比
四、未来展望
在与新一代硬件、云计算技术、人工智能等技术的交汇融合下,数据库技术架构正在持续迭代升级。同时根据Gartner技术报告分析,In-DBMS Analytics库内分析技术将是数据库技术主流发展趋势;未来,从数据产生、集成、建模、执行、管理均在同一平台完成,甚至完全可将分析建模的工作转移到库中。
基于“数据智能”核心技术路径,柏睿数据RapidsDB未来将朝着如下技术发展方向不断演进,助力企业从智慧数据中创造业务新价值。
•库内人工智能:RapidsDB已经可以使用UDF的方式支持库内推理,未来将提供在数据库内的建模、训练、预测等功能,通过领先的人工智能技术为企业提供更加实时的数据处理、更深入的数据洞察和更精确的决策支持。
•索引优化技术:通过建立大量查询索引来为每个表提供技术支持,以实现每个查询都能命中索引,以空间换时间的方式提高查询性能。
•融合新型存储硬件和新一代非易失性内存(NVM)技术:将SSD、NVMe驱动器等新型存储硬件与NVM技术相结合,实现更大的存储容量和更好的I/O性能,更好地处理大规模的数据集和更复杂的应用程序,并确保数据在系统故障或断电等情况下不会丢失。
•多云灵活部署:目前RapidsDB已满足在阿里云、华为云等公有云上部署,支持虚拟化、云原生的私有化部署,未来将更好地支持云原生、自动化部署和管理、弹性扩缩容等功能。