2025-11-28 10:37:13 中华网
AI产业已从“追求模型能力极限”转向“追求推理体验最优化”,推理体验决定用户与AI的交互质感。当前推理应用快速发展,Token调用量爆发式增长,推理遇到“推不动、推得慢、推得贵”三大瓶颈,成为产业规模化发展的拦路虎。在有限算力下,长序列输入导致首Token时延(TTFT)增加,甚至超长序列超出模型上下文窗口限制;随着并发数增加,推理吞吐开始下降,任务频繁卡顿;历史对话和行业知识的重复调用造成算力浪费,加大推理成本。如何优化推理效率,是AI产业突破发展瓶颈的关键。
算力的有效利用对AI推理性能和成本优化发挥着至关重要的作用,是企业核心竞争力。算力平台需适配多元存储、Kubernetes集群及推理框架,但硬件生态碎片化、资源分配僵化、调度缺乏AI任务感知、运维可观性不足等技术兼容难题,正严重制约推理应用发展。
近日,华为数据存储与「DaoCloud 道客」联合推出了AI推理加速联合解决方案。该方案融合了华为UCM(Unified Cache Manager)推理记忆数据管理技术和道客d.run算力调度平台,围绕大模型历史数据,实现KV Cache数据池化管理,以资源的精细化管理和智能调度提升算力利用率,为AI推理加速提供全方位技术支撑。
道客d.run算力调度平台可支持算力与显存资源的细粒度切分及池化,通过多种调度策略实现算力资源的最大化利用。调度器具备拓扑感知能力,可优化任务在xPU间的通信效率,保障AI任务稳定低耗运行。平台提供企业级运维支持,提供多租户隔离、资源配额管理、完整的监控告警及计费计量等功能,满足企业级使用与运维需求。同时具备多元生态兼容性,适配NVIDIA、华为昇腾、寒武纪等多种品牌AI算力,支持TensorFlow等主流AI框架,借助Kubernetes的CSI无缝对接华为OceanStor AI存储,简化管理并为AI任务数据读写提供稳定支撑。
华为UCM是以KV Cache为核心,构建多级缓存空间的分层管理与智能流动机制,实现数据在高性能缓存HBM、内存DRAM和外置OceanStor A系列存储的分级缓存和查询,确保推理记忆知识全量保存。并且,UCM还融合多项创新加速算法:自适应全局Prefix Cache支持公共前缀、历史对话和RAG知识块多种拼接组合场景的复用,通过以查代算,最大程度改善TTFT;全流程稀疏加速算法提供Prefill阶段的超长KV分片卸载和增量稀疏,以及Decode阶段的动态稀疏,提升长序列推理吞吐。
在Qwen3-32B模型上,测试问答助手场景,开启Prefix Cache和RAG Chunk功能。测试数据表明,首Token时延降低约55%,且随着序列长度越长,TTFT降低效果越明显,通过“以查代算”的方式,避免了大量历史对话信息的重复计算。
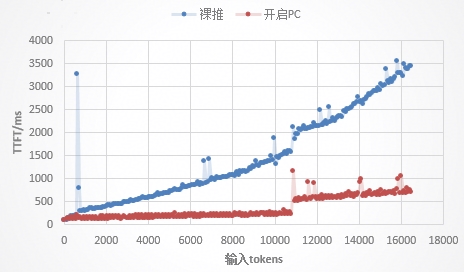
图1 问答助手场景对比开关UCM的TTFT
测试长文档推理场景,设定序列长度输入32K+输出1K,开启Chunk Prefill和GSA稀疏化功能。测试数据表明,在并发数为30时,TTFT最大降低47%,端到端吞吐最大提升75%。
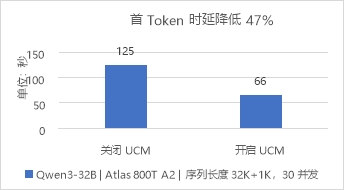
图2 长文档推理场景对比开关UCM的TTFT
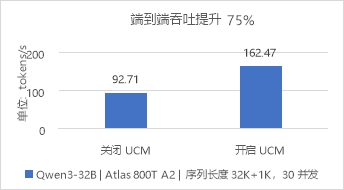
图3 长文档推理场景对比开关UCM的E2E吞吐
关闭UCM,当并发数超17时,请求开始排队;开启UCM,当并发数超32时,请求开始排队。在以上情况下,开启UCM对比关闭UCM场景,并发能力提升88.24%。
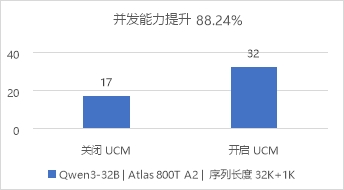
图4 长文档推理场景对比开关UCM的并发能力
目前,该方案正在电力、金融等行业试点。未来,双方将持续深化技术合作,推动技术迭代与行业适配,助力AI技术在更多行业的落地应用。