2025-11-19 14:30:32 中华网
相比传统的 Two-Batch Overlap,Token 双流(Two-Chunk Overlap)通过 token 级细粒度划分,在请求长度高度异构的真实业务场景中显著提升了计算和通信 overlap 效率与 GPU 利用率,同时严格保证推理结果正确性,无精度损失。
在百度百舸线上真实业务中(约束首 token 延迟 TTFT < 1 秒),单机吞吐最高提升达 30%。
在 25 年 8 月百度百舸将Token 双流核心代码正式贡献至 SGLang 开源社区。
代码地址:https://github.com/sgl-project/sglang/pull/8144/
让计算和通信真正并行
在大模型推理系统中,一个核心设计目标是:让计算和通信尽可能并行执行——当一部分 GPU 在进行前向计算时,另一部分可以同时发起通信(如 AlltoAll、AllGather 等),从而通过重叠隐藏通信延迟,最大化硬件利用率。
为实现这一目标,社区广泛采用Two-Batch Overlap(TBO)技术:将一个 batch 拆分为两个 micro-batch,在层(layer)维度交错执行。具体而言,系统交替处理两个 micro-batch 的各层计算,并安排其中一个 micro-batch 的计算与另一个 micro-batch 的通信在时间上并行,形成流水线式的重叠。
然而,TBO 的高效运行依赖一个关键前提:两个 micro-batch 的计算和通信耗时相近。但在真实业务场景中,用户请求长度高度异构——有人提交近 3000 token 的长文档,也有人只发几十 token 的短指令。此时,按 sequence 粒度拆分会导致两个 micro-batch 负载严重失衡,重叠窗口坍缩;极端情况下(如单条长请求),甚至需要构造空的 idle batch 来维持双流调度结构,造成 GPU 资源浪费。
如何让 overlap 策略真正适配真实负载,在保持低首 token 延迟的同时发挥最大性能?这正是我们提出Token 双流(Two-Chunk Overlap)的出发点。
从 Batch 双流到 Token 双流:更细粒度的 Overlap 调度
传统 TBO 按完整sequence 粒度划分 micro-batch。例如:
●请求 A:2900 tokens;
●请求 B:100 tokens。
TBO 会将其划分为:
●micro-batch0:[A](2900 tokens);
●micro-batch1:[B](100 tokens)。
由于两者计算量相差近 30 倍,系统无法有效安排计算与通信的并行窗口——短请求对应的 micro-batch 很快完成所有计算操作,而长请求仍在通信,导致 GPU 大部分时间负载很低。若 batch 中仅有一条长请求(如 3000 tokens),TBO 仍需构造一个空的 micro-batch 以维持双流调度框架,进一步降低资源利用率。
Token 双流则改为在token 粒度动态切分序列,使两个 micro-batches 的计算负载尽可能均衡。
仍以上述例子说明:
●将请求 A(2900 tokens)拆分为两个 chunk:前 1500 tokens 和后 1400 tokens;
●将请求 B(100 tokens)与 A 的后半部分合并。
最终得到:
●micro-batch0:1500 tokens(A 的前半);
●micro-batch1:1500 tokens(A 的后半 + B)。
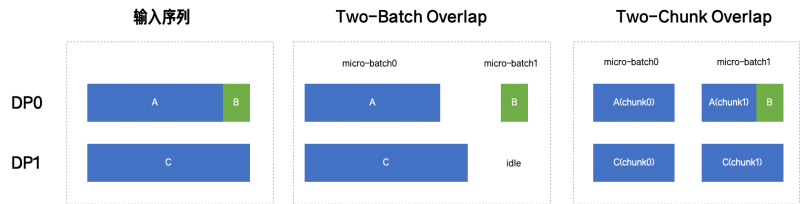
这样,两个 micro-batch 的计算和通信时间接近,系统可有效安排交错执行,使计算与通信充分重叠。即使只有一个长请求,也能被均分为两个等长 chunk,彻底避免 idle batch。
该方案适用于 MLA、GQA、MHA 等各类注意力机制,已在 DeepSeek、Qwen 等模型架构中验证有效。
值得注意的是,这种切分方式不会影响模型输出的正确性。Two-Chunk Overlap 在执行时确保第二个 chunk 的第i层计算总是在第一个 chunk 的第i层完成后才开始,并将第一个 chunk 生成的 KV Cache(或 latent 状态)作为 prefix 缓存传递给第二个 chunk。因此,整个前向过程与原始完整 sequence 完全等价,推理结果在数值上严格一致。
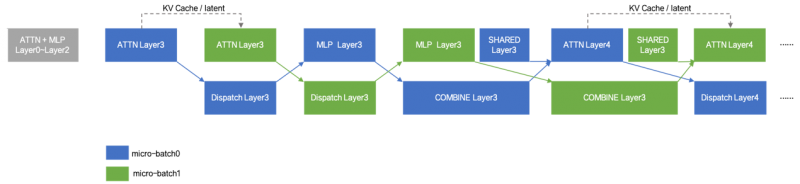
为兼顾通用性与性能,系统支持动态启用策略:当按 batch_size 拆分导致两个 micro-batches 的 token 数比例超出 [0.9, 1.1] 区间时,自动触发 chunk 划分。该行为可通过 --tbo-token-distribution-threshold 参数调节。
线上业务验证:从生产环境到 SGLang 社区
百度百舸团队于 2025 年 5 月在内部完成 Two-Chunk Overlap 的实现,并将其部署于线上复杂业务场景,至今已稳定运行超过半年。2025 年 8 月,我们将核心代码正式贡献至 SGLang 开源社区(GitHub PR#8144)。
我们在 2×8×H800 集群上基于 DeepSeek-V3-0324 模型进行了多组对比测试。在单一长请求场景(每 DP 节点处理一条 3072 token 请求)下,Token 双流相比传统 TBO 实现了 12.56% 的吞吐提升;在通用变长请求场景(请求长度在 30 至 3072 tokens 之间随机分布)下,吞吐提升为 5.15%;在百度百舸线上真实业务中(约束首 token 延迟 TTFT < 1 秒),单机吞吐最高提升达 30%。