2025-06-23 15:51:12 中华网

在语音 AI 不断迈向“人机无感交互”的今天,双工对话(Full-Duplex Conversation)正在成为技术发展的新高地。人类习惯的对话方式不是你说我听、轮流发言,而是可以“边听边说”、伴有“打断、犹豫、回应词”的自然交流。而要构建具备这一能力的语音交互系统,仅靠算法远远不够,真实、高质量的语音数据是基础中的基础。
为什么是日语双工对话数据集
日语是语音合成和语音识别领域中一个长期被低估、但应用潜力极大的语言。典型应用场景包括:
1、二次元互动角色语音
日本的二次元文化风靡全球,动漫、游戏产业规模庞大。在这一领域,语音交互技术可实现更自然的角色对话、游戏指令识别等功能,自然、反应快、有情绪的语音能力都成为刚需。例如,玩家在沉浸式游戏中,通过日语语音与游戏角色进行实时互动,增强游戏的趣味性与代入感;动漫配音也能借助 AI 技术实现多样化创作,为二次元爱好者带来全新体验。

2、车载语音导航系统
日本汽车产业高度发达,语音控制已成为车载系统的核心接口之一。驾驶过程中,语音助手必须支持快速打断、命令切换、并行处理,避免传统系统的“卡顿等待”体验。实现这一点的基础,正是训练于双声道、可打断、跨语义段的数据集。
3、老龄化社会中的陪伴 AI
面对加速老龄化的社会现实,日本涌现出大量基于语音交互的智能陪伴机器人、健康问诊设备与居家看护系统。系统需要理解老年人的语速变化、犹豫表达,甚至识别微妙的语气差异,以提供及时反馈与情绪陪伴。这对数据的自然度、打断处理、语气还原提出了极高要求。
Magic Data 开源日语双工对话数据的独特优势
面对上述多样化、复杂化的日语语音应用场景,Magic Data 所发布的日语双工对话数据集不仅填补了市场空白,更在数据设计与应用层面展现出四大核心优势,为研究实验与实际产品部署提供稳固支持:
1、双声道高保真录音,精准还原“边听边说”
每段对话均采用双声道采集,一人一轨道,确保语音重叠、打断、应答词等双工特征在数据中清晰可分离。这不仅极大提升了模型训练精度,也为语义VAD、说话人识别、语气识别等任务提供丰富素材。
应用示例:在汽车语音助手中,系统可准确识别驾驶者的打断指令并即时响应。
2、针对性用词标注,语言结构更友好
我们针对日语独特的书写系统,根据日常对话用语的特点,针对性使用适合的汉字、平假名、片假名的标注方式,更贴近真实生活。此设计既方便 NLP 层对语言的深度理解,也提升了语音合成在自然度、节奏感与语感连续性方面的表现。
应用示例:面向动漫角色的语音合成训练,可根据角色属性选择不同假名风格、调控语气。
3、真实对话语料,覆盖自然情感与表达方式
本数据集对日常语音中的“语气词(えっと、あの、えー)”、“附和词(はい、うん、そうですね)”、“补充/打断行为”都进行了精细标注,使训练出的模型更能捕捉用户真实情绪与语用习惯,避免“机器人感”。
应用示例:在健康管理语音助手中,系统能识别老年人犹豫或迟疑背后的情绪波动,提升服务贴心度。
4、多场景覆盖 + 可扩展商用 OTS 数据集,灵活适配产品部署
除开源数据外,Magic Data 也为企业级使用提供了更大规模的 OTS 商用数据集。数据内容涵盖文化、生活、陪伴等多个典型场景,并覆盖了多样化的录音人,风格自然度高。如企业或团队有更大规模需求(千小时级),Magic Data 立等可取的商用数据集可以快速帮助企业完成语料构建与模型适配支持。
应用示例:开发者从开源数据起步,在模型初步训练后,可通过企业商用 OTS 数据集合作快速完成产品级语音优化。
这套数据集能帮谁?
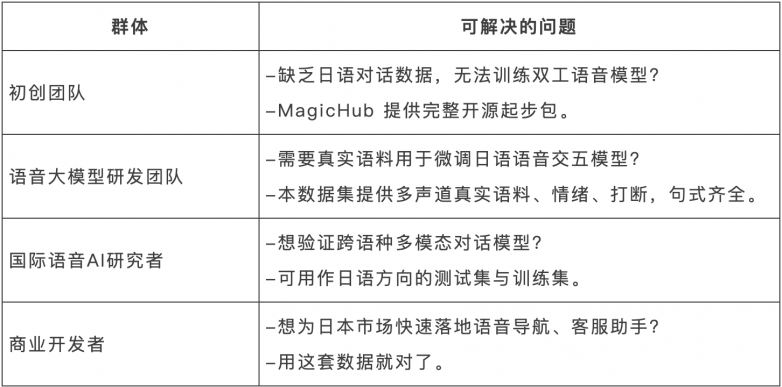
数据使用建议
1、多模态语音双工对话系统
- 为基于音频、文本、情绪的双工建模提供真实自然、多样化的语料。
2、语音合成(TTS)情绪建模
- 用于训练包含停顿、语气词的自然语音合成系统。
3、语音识别理解训练(ASR & Understanding)
- 可直接用于识别模型训练并帮助构建理解模型,使得模型更好的做理解分析。
4、语音活动检测(VAD)与交互控制
- 构建基于语义的发言控制机制。
十小时开源,千小时积淀:日语双工对话数据的打磨之路
这套数据的开源并非一蹴而就。从真实使用场景调研、多轮对话语料设计、到语音采集流程的质量把控与高标准多层级标注体系,每一个环节都经过了反复打磨。这不仅是对日语口语交互真实语感的精准还原,更是为突破双工语音交互技术瓶颈所做的基础性工作。
我们希望借由这套数据:
- 帮助更多团队和研究者少走弯路;
- 推动日语语音 AI 的生态建设;
- 也为跨语种 AI 模型的多元化发展提供一块“拼图”。
如果你对大规模日语双工对话语音数据集有更高需求,或者想要扩展到更多日语场景,欢迎联系我们,我们可提供上千小时的 OTS 可商用语音数据集,能够根据开发者的不同场景需求,定制化提供高质量的数据解决方案,助力开发者在日语语音交互技术领域取得更大突破。
前往MagicHub平台即可下载日语双工对话开源数据集,免费用于您的学术研究。