2024-06-14 19:49:12 中华网科技
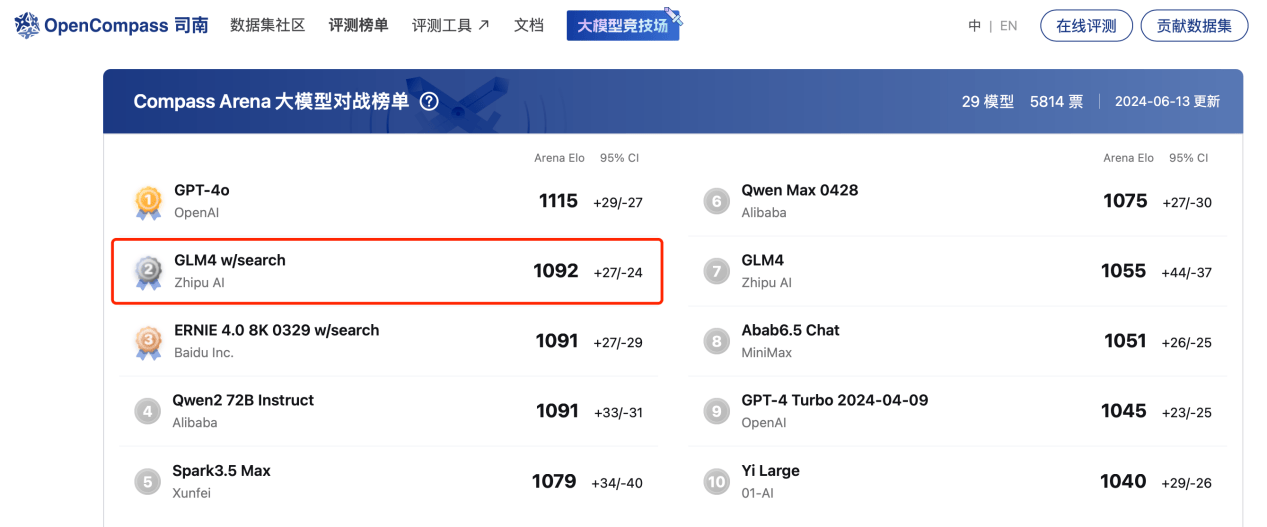
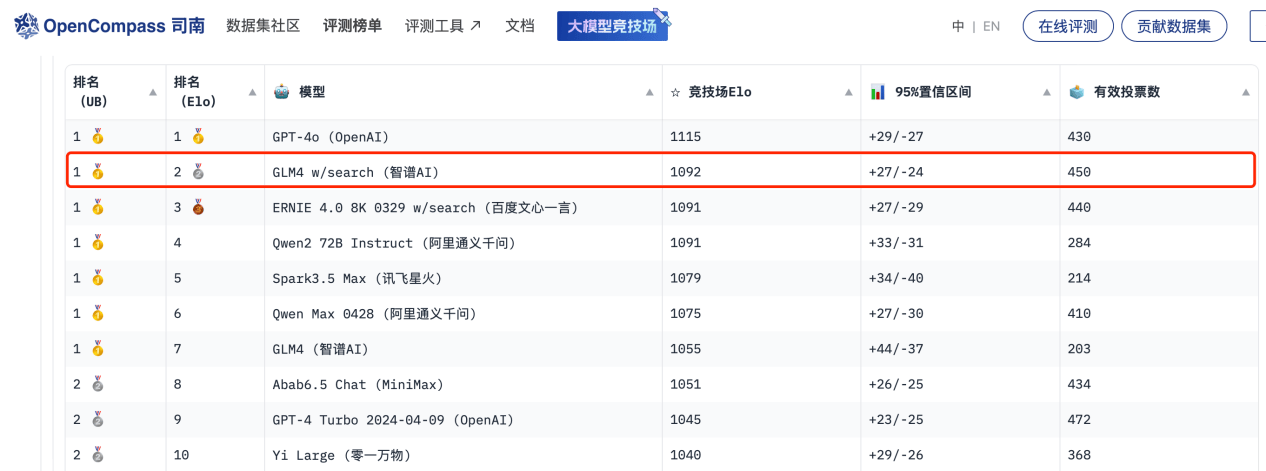
6月13日,司南OpenCompass和魔搭ModelScope联手推出的大语言模型竞技场 Compass Arena公布首期大模型对战榜单。智谱AI的GLM-4 w/search 排名仅次于GPT-4o,位列国内大模型第一。相比 GLM-4,GLM-4 w/search 可以在交互过程中引入外部搜索引擎信息辅助内容生成。
Compass Arena司南大模型竞技场是由司南OpenCompass团队和魔搭ModelScope团队共同推出的大语言模型 (LLM) 评测平台,旨在为国内的大语言模型领域引入一种全新的竞技模式,为广大互联网用户提供了一个匿名、随机的大语言模型竞技环境,以产生更加客观和真实的评价。Compass Arena汇集了Qwen-Max、GLM-4、abab6.5以及Llama 3系列等 20 余个主流大语言模型,通过创新的竞技模式,让用户在直观体验比较不同模型的性能后,根据自己对生成内容质量的主观判断,自由评估选择生成效果更为出色的大模型。
Compass Arena大模型竞技场首期对战榜单收集了截至6月12日接近6000条由用户真实反馈的大模型匿名对战数据,经过数据清洗和过滤后利用Bradley-Terry模型估计了大语言模型的竞技场Elo等级分数和95%置信区间,并使用该等级分数对大模型进行排名。榜单中,智谱AI的GLM-4 w/search凭借回答环节引入外部搜索引擎信息能力的辅助,有效提升了生成内容的准确性和完整性,排名仅次于GPT-4o位列第二名,成为Compass Arena大模型竞技场首期对战榜单国内大模型第一名。
值得一提的是,智谱AI的GLM-4系列模型自发布以来便收获业内及广大用户认可,并多次在权威榜单与全球顶级大模型一较高下。清华《SuperBench大模型综合能力评测报告》显示,GLM-4在语义理解等方面的能力表现超过众多国际一流模型,在代码、智能体等方面,排名国内第一。在SuperCLUE-Fin(SC-Fin)中文原生金融大模型测评基准中,GLM-4斩获一项A+及多项A级评价,在国内大模型中排名第一。
据了解,智谱AI于今年1月推出新一代基座大模型GLM-4,并在6月初发布最新开源模型GLM-4-9B,该模型拥有更强的基础能力,支持更长的上下文(最高支持1M/约两百万字),有更精准的函数调用和All Tools能力,并在这个尺寸上首次具备了多模态能力。GLM-4-9B综合能力相比ChatGLM3-6B提升40%,全面超过Llama-3-8B-Instruct,中文学科能力提升50%,最高支持达1百万tokens长文本,支持多达26种语言,函数调用(Function Call)能力媲美GPT-4-Turbo。
上述模型均已在智谱AI MaaS大模型开放平台上线,开发者可以通过bigmodel.cn便捷接入GLM-4全系列模型开放API,从而体验智谱大模型的卓越性能。