2024-04-09 17:21:27 十安热线
一直以来,超级计算机因其无可匹敌的运算实力而在科研界享有“巨擘”之称,大众耳熟能详的莫过于那些荣登全球超算Top500排行榜的翘楚品牌,如Frontier和神威·太湖之光等,它们展现出了卓越的通用高性能计算能力。然而,在生物计算这一细分领域中,即便是这些巨头也会显得有些“力不从心”,难以全面应对诸如大规模分子动力学模拟、蛋白质三维结构预测等极具挑战性的任务。这时,就不得不提在生物计算领域占据显著地位的专用超级计算机安腾(Anton)了。

安腾超级计算机 图片来源:D.E. Shaw Research
安腾超级计算机是由美国D. E. Shaw研究所于2007年首次发布,专门用于对生命科学研究和生物制药研发领域至关重要的算法——分子动力学模拟算法的加速。在计算分子动力学模拟(Molecular Dynamics, 简称MD)问题时,超算安腾的计算效率比全球最强的超算Frontier还要高上数十倍。
为什么安腾超级计算机能比美国Frontier算得还要快?
秘诀就在于安腾超级计算机的“专项定制”属性。安腾超级计算机由大量的特定应用集成电路(ASIC)组成,通过一个专门的高速三维环形网络相互连接 。不同于通用超算的一刀切设计,超算安腾的架构专为细粒度事件驱动而设计运算,通过增加计算与通信的重叠来提高性能。
由于安腾超级计算机主要专注于分子动力学模拟加速,即其所应对的主要任务属于通讯密集型的并行计算范畴。在此背景下,超算安腾在芯片设计、通信网络这两个方面进行了特殊设计,从而有效提升此类任务的计算效率。
512个深度定制ASIC芯片提供强大算力支持
首先,在硬件层面,由于CPU、GPU等通用的算力芯片无法满足特定问题对算力性能的要求,因此,专用超级计算机常常选择搭载ASIC芯片(即专用集成电路),以针对性地提供解决特定问题所需的强大算力支持。

安腾超级计算机的核心优势就在于其使用的512个MD专用ASIC芯片。这些芯片经过深度定制,具有针对性强的指令集架构(ISA),能够精确执行分子动力学模拟(MD)中最耗时和最频繁的计算任务,如分子间的长程和短程相互作用力的计算,为这些关键计算步骤提供硬件算法层面的性能优化,例如快速傅里叶变换(FFT)等算法。

图片来源:D.E. Shaw Research
同时,为了减少计算延迟,安腾超级计算机还设计高度专业化的专用硬件数据路径和控制逻辑,用于评估范围受限的相互作用,并执行电荷扩散与力插值。除了在芯片上密集整合高度定制化的计算逻辑之外,这些流水线还针对每个操作都采用了定制化精度。
“量体裁衣”般的并行计算硬件设计只为提升计算性能
GPU、通用超算等通用的计算架构更多关注的是访存密集型任务的优化,而超算安腾则是针对通讯密集型的并行计算问题进行了特化优化。因此超算安腾在处理高度依赖大量通讯密集型并行计算的分子动力学计算任务时,自然就会比传统的通用超级计算机架构多出许多天然的优势。
具体来说,超算安腾上运算的分子动力学算法的主要应用领域之一是对蛋白质进行的仿真模拟。这类仿真模拟任务需要计算机记录当前每个原子的位置、运动状态等,之后利用分子动力学模拟计算这些粒子之间相互影响的运算结果。在这样的情况下,每个节点需要承担的运算并不复杂,所以并不需要每个计算单元具有极其高强的计算能力;也不需要大规模数据的输入输出存,所以也不是访存密集型任务。因此在设计上,安腾超级计算机取消了其它并行计算硬件中十分常见的缓存,也就是不需要很大的存储空间。
例如,对于一个包含25,000个粒子的MD模拟,其整体架构状态只需要1.6兆字节,放到一个由512个节点构成的系统中,每个节点仅占用3.2千字节。鉴于此特性,超算安腾选择在ASIC上仅仅配备SRAM和小型L1缓存,并确保在常规操作条件下,所有的代码和数据都能够妥帖地装载在芯片之上,没有把宝贵的硅片面积用于构建大型缓存或是复杂的内存层级结构,而是将这些资源重点投入到通信和计算性能的提升上。
此外,分子动力学模拟中,最为消耗计算资源的是分子间的长程相互作用力的计算,如静电相互作用等。据统计,在通用处理器上运行的标准MD模拟中,计算静电和范德华力所耗费的时间占到了总体计算时间的约90%。由于这些力的计算都是基于成熟的物理原理和公式得出的,不太可能随力场模型进化而发生巨大改变,基本因此非常适合硬件加速。但是,要想实现MD模拟的显著提速,光是加速这些“核心循环”还不够,还需要对其他相关的计算任务进行同步加速。依据阿姆达尔定律,即使把前述占用90%计算时间的任务的计算效率大幅优化,如果其余10%的计算任务还是维持现状的话,整个系统的最大加速比也只能达到10倍左右的上限。因此,超算安腾特意划拨了相当一部分硅片面积用于加速那些诸如键力计算、约束条件计算、速度和位置更新等其他关键任务。
服务器摆放与网络结构的特殊设计有效提升通讯效率
在通信层面,由于分子动力学模拟是一种需要大规模并行化的计算密集型方法,因此快速并行分子动力学模拟的实现就需要节点间通信的高带宽和低延迟。为提高通讯效率,安腾超级计算机也做了一些特别的设计。
例如,整个超算安腾的服务器都被紧密地摆放在一个正方体的机箱中,这样的好处在于节点之间依靠网络互联,紧密排列使得网络的传输距离大大降低,可靠性和速度大大提升,所以速度有了很大的提升。
又比如,超算安腾设计了独特的内存子系统,专门用于积累每个粒子所受的力,这样可以减少计算过程中必要的数据交换。为了进一步提高计算效率,安腾超级计算机采用了低延迟、高带宽的网络结构,不仅在单个ASIC芯片内部实现了快速通信,还在不同ASIC芯片之间也建立起了高效的互联网络。这个网络特别支持常见的MD通信模式,比如多播和稀疏数据结构的压缩传输,同时也支持协调式的“推送”式通信方式,即生产者主动将结果发送给消费者,无需消费者预先请求数据。此外,系统中还配备了一系列独立的直接内存访问(DMA)引擎,用于卸载计算单元的通信任务,使得通信和计算过程能更紧密地重叠执行,从而最大程度减少等待时间。
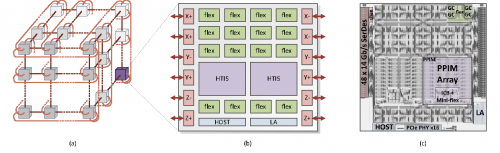
ASIC芯片通过高速通道直接连接,形成三维环形拓扑结构
图片来源:D.E. Shaw Research
通过以上分析可见,安腾超级计算机通过一系列精密的硬件和软件协同设计,聚焦于加速分子动力学模拟的关键环节,使得其在处理大规模生物分子系统长达百微秒级别的经典分子动力学模拟时表现出前所未有的高效性。
安腾超级计算机的技术路线无疑为我国超算领域、尤其是专用超算领域的技术研发提供了路线借鉴参考。在生物制药、生命科学、新能源新材料等前沿科技火热发展的重点垂直领域,我们应当加强全栈式的软硬件协同创新,挖掘在特定计算难题上的重大产业和创新机会,不断提升在全球超算竞赛中的竞争力与影响力。