2023-12-29 18:08:46 快讯
2023年11月28日,中电信人工智能科技有限公司(以下简称:电信AI公司)落户西城区。它是中国电信开展大数据及人工智能业务的科技型、能力型、平台型专业公司。2023年,电信AI公司在全球21场顶级AI竞赛中屡获殊荣,申请专利100余项。同时,该公司在CVPR、ACM MM、ICCV等权威会议和期刊上发表了30余篇论文,充分展现了国资央企在人工智能领域的实力和决心。
该公司注册资本为30亿元,前身为中国电信集团的大数据和AI中心。作为一家专注于人工智能技术研发和应用的公司,他们致力于核心技术的研究、前沿技术的探索以及产业空间的拓展,旨在成为百亿级的人工智能服务提供商。在过去两年里,该公司自主研发了星河AI算法仓赋能平台、星云AI四级算力平台以及星辰通用基础大模型等一系列创新的成果。目前,公司员工规模超过800人,平均年龄仅31岁。其中,研发人员占比高达80%,且70%的员工来自国内外知名互联网企业和AI领军企业。为了加速大模型时代的研发进程,公司拥有超过2500块等效于A100的训练卡,并配备了300多名专职数据标注人员。此外,公司还与上海人工智能实验室、西安交通大学、北京邮电大学、智源研究院等科研机构紧密合作,结合中国电信6000万视联网和数亿用户场景,共同推动人工智能技术的创新和应用。
接下来,我们将对电信AI公司在2023年的一些重要科研成果进行系列回顾和分享。本期是针对电信AI公司TeleAI团队在ChaLearn Face Anti-spoofing Challenge at CVPR 2023竞赛中上获得了互联网赛道冠军的技术介绍。CVPR是计算机视觉领域的三大顶会之一,该会议每年举办一次,在计算机视觉领域具有极高的影响力和地位。本文将介绍该团队在本次挑战中采用的算法思路和方案。
ChaLearn Face Anti-spoofing Challenge at CVPR 2023 Track :Face Anti-spoofing in the wild 冠军技术分享

【赛事概览与团队背景】
近年来,人脸识别系统的安全性日益受到威胁。人脸活体检测(FAS)是保护人脸识别系统免受各种攻击的关键。为了吸引研究人员,推动人脸活体检测技术的发展,CVPR2023开展了专题竞赛。目前,基于监控场景的远距离人脸呈现攻击仍然是一个威胁。具体而言,与手机开锁、人脸支付、自助安检等传统场景的活体检测相比,车站广场、公园、自助超市等远距离场景的活体检测同样重要,但尚未得到充分的探索。CVPR2023的挑战赛将侧重于更一般的监视和野外场景,着重解决活体检测技术在低人脸分辨率、遮挡干扰、非正面视角和其他自然人行为下的性能下降。充分考虑到上述困难和挑战,发布了两个数据集,开启两个活体检测赛道。本次参加的赛道为Wild Face Anti-Spoofing (WFAS)的大规模互联网赛道,其中发布的数据集包括148,169个身份的529,571张活体图像和321,751个身份的853,729张欺骗图像。
由中国电信AI公司活体算法方向的成员组成的TeleAI团队,参加了本次比赛。该团队在计算机视觉技术这个研究方向深耕,积累了丰富的经验。他们的技术成果已在营业厅、线上智能客服等多个业务领域中广泛应用,持续服务海量的用户。而且,团队的活体检测技术已经通过了信通院、银行卡检测中心(BCTC)、公安一所三个权威认证。TeleAI团队以本次CVPR 2023的活体检测大规模互联网赛道为契机,实现在活体检测领域的自我突破。
1引言
尽管目前的活体检测方法在传统场景中取得了很好的表现,但在大规模互联网场景中活体检测仍然是一项具有挑战性的任务。与传统场景相比,大规模互联网场景活体检测存在诸多困难。互联网采集的人脸通常分辨率分布广泛,最低的分辨率仅50*50,传统的活体检测模型无法很好地处理。由于不同的背景和设备以及其他噪音,互联网环境更加复杂。通常采集的人脸图像是非正面视角:侧视脸,这些姿态涉及了自然人的行为。

本赛道规定参赛者不能使用额外的数据以及预训练模型,并且模型大小限制在5 Gflop。TeleAI团队因此决定从蒸馏学习和数据增强技术出发进行设计,并采用半监督学习方式增强活体检测在互联网场景下的能力。整个算法流程分为三部分,首先,TeleAI团队使用自蒸馏学习策略训练一个自监督Vit-small模型以获得较好的预训练模型;然后用标记好的训练数据微调自监督预训练的Vit模型;最后,模型可以对数据进行预测来生成“伪标签”,并用来重新训练模型,以进一步提高其性能和泛化。TeleAI团队的方法在人脸活体检测竞赛@CVPR2023的大规模互联网赛道中获得第一名。TeleAI团队的最终提交成绩分别获得了1.29%的APCER, 1.90%的BPCER和1.60%的ACER,比竞赛中第二名的成绩2.22%超出0.62个百分点。
2 竞赛解决方案

图1 算法概览
2.1 自监督训练
本赛道禁止使用任何其他数据训练的预训练模型参数,包括Imagenet预训练模型。为了弥补无预训练模型参数带来的损失,TeleAI团队首先想到使用训练数据进行自监督学习来获得类似于Imagenet预训练模型参数的效果。TeleAI团队使用自蒸馏学习策略训练一个自监督Vit-small模型,算法框架图如上图所示。
首先,使用训练数据进行不标签的自监督学习。对输入图像执行两种不同的数据增强变换,分别将它们输入到学生网络和教师网络。两种网络结构相同,但模型参数不同。算法将它们的输出表示为P1和P2,使用P2作为P1的目标。P2是教师网络的输出,以一个批次的数据上计算的平均值为中心。最终使用交叉熵损失来度量它们的相似性,损失函数为:
230251045085
其中对教师网络应用一个梯度停止算子,损失函数只用来更新学生网络。教师的参数是用学生的指数移动平均来更新(动量编码器),更新公式如下:
211137581915
通过对训练数据的多次自监督训练,此时的教师网络模型参数被TeleAI团队当作预训练模型参数,和Imagenet预训练模型一样,此时的模型还不具备活体检测能力。
2.2 活体检测能力
活体检测是一个二分类问题,因此活体模型要求能够根据输入数据将其正确分类为两个不同的类别之一。为了达到这个目标,我们需要定义一个损失函数来度量模型在训练过程中的性能。
交叉熵损失(Cross-Entropy Loss)是一种常用的损失函数,特别适用于二分类任务。它基于信息论的概念,可以衡量模型的预测结果和真实标签之间的差异。在二分类任务中,我们通常使用sigmoid函数作为模型的最后一层。这个函数将模型的输出压缩到0到1之间,表示属于正例的概率。对于每个样本,模型会输出一个概率值,我们可以将其解释为该样本属于正例的可能性。

交叉熵损失的计算方式如下:
其中,y表示真实的标签(0或1),yi表示模型的预测概率。该损失函数可以量化模型的预测结果与真实标签之间的差异。当模型的预测接近真实标签时,交叉熵损失趋向于0;反之,当模型的预测与真实标签差距很大时,交叉熵损失会变得很大。通过最小化交叉熵损失,我们可以训练模型的参数,使其能够更好地预测样本的类别。具体来说,通过优化算法(如梯度下降),我们可以调整模型的参数,使得交叉熵损失不断减小,从而提高模型的分类准确性。
2.3 半监督学习
在机器学习的快速发展中,半监督学习作为一种独特的方法,越来越受到研究者的关注。这种方法结合了监督学习和无监督学习的优势,利用一部分有标签的数据和大量的无标签数据,使得模型在有限的标注数据下能够取得更好的泛化能力。
在预训练模型预测的基础上,我们选择预测结果中置信度高的数据,通常依据yi。这些数据被认为是模型较为确定的结果,对于后续的半监督学习具有重要意义。将置信度高的预测结果作为伪标签,重新加入模型训练。这一步是半监督学习的核心,通过不断迭代,模型能够从伪标签中不断学习并改进自己的预测能力。
3 实验结果
3.1 评估指标

评估指标与传统场景中的活体检测任务一致,包括攻击呈现攻击分类错误率(APCER)、活体分类错误率(BPCER)和平均分类错误率(ACER)。计算公式如下:
其中,FP、FN、TN、FP分别为假阳性、假阴性、真阴性、真阳性样本数。在活体竞赛大规模互联网赛道@CVPR2023中ACER指标被用来确定最终排名。
3.2 实验细节
TeleAI团队所使用的模型结构就是一个经典的Vit-small模型。首先,Vit模型按照自监督学习算法进行训练,使用AdamW优化器训练和初始学习率lr为5e-4,采用余弦学习率schedule (CosineLR)对lr进行调整,最小学习率为1e-7。共进行150轮自监督训练。然后仅修改初始学习率为2e-6,以同样的设置进行二分类微调,共训练20轮。最后和微调参数一样,进行25轮半监督训练,进一步优化活体检测能力。
3.3 比赛结果
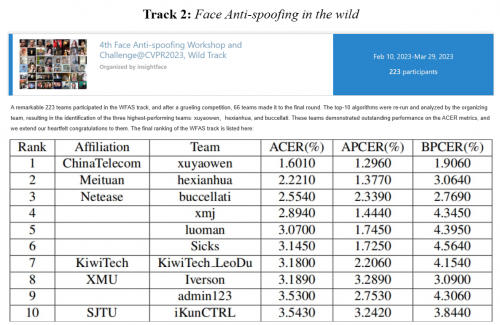
共223支队伍参加了CVPR2023活体检测互联网赛道的比赛,经过艰苦的比赛,66支队伍进入了最后一轮决赛。组织方对前10名的算法进行了重新运行和分析,最终确定了前三名分别是TeleAI团队、美团团队、网易团队。这些团队在ACER的指标上表现出色,下表是比赛时最终成绩:
4 结论
TeleAI团队在CVPR2023的人脸活体检测竞赛中以卓越的表现脱颖而出,获得了第一名。他们的方法主要基于蒸馏学习和数据增强技术,并采用了半监督学习方式来提高模型在互联网场景下的活体检测能力。团队的方法在APCER、BPCER和ACER指标上分别达到了1.29%、1.90%和1.60%。与竞赛中第二名相比,TeleAI团队的成绩超出了0.62个百分点,显示出他们在人脸活体检测领域的优秀表现。
这次比赛对TeleAI团队来说是一次宝贵的经验和成长机会。他们充分利用了蒸馏学习和数据增强技术,通过自监督训练和模型微调取得了突出的结果。同时,采用半监督学习方式进一步利用“伪标签”进行模型训练,也展现了团队对于资源有限情况下的创新思维。TeleAI团队在CVPR2023人脸活体检测竞赛中的第一名成绩是他们努力和创新的结果。他们的方法不仅在互联网场景下取得了出色的活体检测表现,也为未来的研究和应用提供了有价值的参考。