2023-12-08 14:50:14 中华网科技

作者:秦鸿林紫羚云 CGO、资深解决方案专家
一、背景介绍
在之前的一篇《紫羚云秦鸿林:数字化时代,如何认识和对齐 ITSM 价值》文中,提到实施ITSM的第一个场景就是“IT基础设施和数字化产品的运维,也就是基础和系统运维层面”,这里的一个重要价值就是提升业务连续性。
对于大中型企业,或者已经信息化、数字化转型到一定程度的企业,基础设施,核心业务系统的可用性(有些企业,为了好理解直接叫在线率)至关重要,系统宕机,直接影响业务,甚至会直接造成财务损失,影响企业声誉。
其实对于对行业或市民生活有重大影响的公共基础设施更是如此,无独有偶,对咱们日常生活有重大的影响的基础设施故障频发。
事件1:12月3日,“腾讯视频崩了”登上微博热搜
事件2:12月1日上午,上海市医保系统崩溃无法进行医保结算
事件3:11月27日23:13 滴滴出行APP崩溃
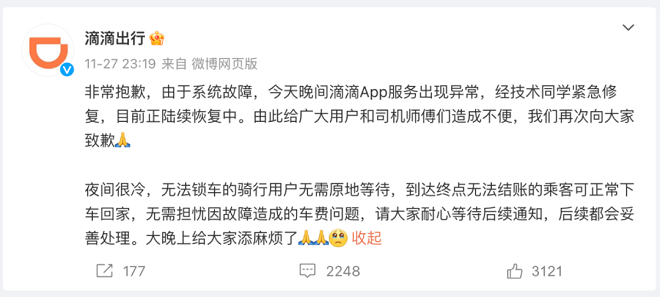
11月27日23:13 上海、北京、广州等多地滴滴用户反馈,滴滴出行APP无法使用,用户无法正常打开滴滴打车界面、地图无法加载、司机无法确认乘客上车状态、乘客无法确认司机位置、青桔单车无法扫码……滴滴系统服务故障在社交平台上“轰轰烈烈”上演了一整天。
11月29日,滴滴再次致歉,并公布故障原因。滴滴表示,在各项服务恢复的同时,企业于28日启动了内部复盘调查。初步确定,这起事故的起因是底层系统软件发生故障,并非网传的“遭受攻击”,后续将深入开展技术风险隐患排查和升级工作,全面保障服务稳定性,尽最大努力避免类似事故再发生。
事件4:11月12日晚间,阿里巴巴旗下淘宝、闲鱼、阿里云盘、饿了么、钉钉在内的多款产品均出现了服务器故障问题,疑似无法正常操作
实际上,上述不管哪一起事件,如果我们去网上仔细搜索,就可以轻易发现都不是第一次,包括滴滴三年崩了四次(2022年9月22日、2021年2月25日、2021年3月1日),而作为全球第三名云厂商的阿里云(据IDC2022年的报告,全球前三名云厂商依次为亚马逊、微软、阿里云,其中阿里云以6.2%份额位居全球第三)更是6年4次。这样的事件,对企业不管是财务和声誉的损失都是巨大的。
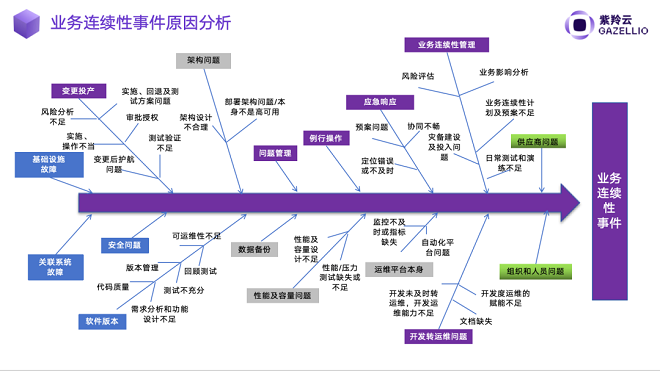
二、影响业务连续性的重大事件原因分析
影响业务连续性的重大事件究其原因,其实是比较多的,原因也比较复杂。有的是机房设施、变更操作、版本问题、操作失误、网络问题等等。这次滴滴系统崩溃之后,就有SRE领域的运维专家,在《2023-11-27滴滴故障原因解密》中对该起事件做了分析,大致是将原因归结为是k8s集群升级时kubelet版本升级时,版本选择错误,由升级反倒变为了降价,另外由于是“原地升级”的方式,导致回退异常困难。并且总结了四个启示:升级的半径不宜过大、回滚一定要可靠、重大变更的控制、不要在人困的时候做变更。其实,这些都是属于ITIL和ITSM变更管理的范畴。
笔者从ITIL(ITIL 全称Information Technology Infrastructure Library,通常被译为“信息技术基础架构库”)和日常经验罗列了影响业务连续性的一些原因,供大家参考,里面很大一部分在互联网,云厂商可能不会出现:
基础设施故障:在IaaS、PaaS等底层问题,或者说云平台或机房设施、计算、存储、网络等基础设施硬件本身问题,属于被牵连被影响。
关联系统故障:关联系统或上游系统故障导致的接口或局部功能受到影响。
安全问题:安全漏洞,被攻击等。
变更投产:变更前的风险分析不足、变更实施方案和测试方案不到位或者没有经过授权或充分讨论、变更后的测试验证不充分、变更后的监控和护航缺失、变更误操作。
软件版本:软件版本本身的问题,例如产品或功能设计不足、代码质量、版本控制、应用逻辑等测试不充分仓促上线后。
常见的问题是在开发封板、功能测试、集成测试、UAT测试修改bug后,因为时间紧迫没有充分的回归测试,甚至是上线前还在改代码,导致改bug产生了更大的bug出现。
架构问题:架构设计不合理,容错设计不足、部署架构本身不是高可用架构,或者不是真正的高可用架构,例如高可用架构中有单点。
性能及容量问题:因为架构设计或者性能、容量评估不足,性能测试和压力测试不到位导致的灾难;
问题管理:前期故障没有根本解决,复盘或根因分析不到位,重大事件和问题管理没有闭环等。
例行操作:日常监控和巡检不足、监控不及时、监控指标缺失等,导致风险和隐患没有及时被发现。
数据备份:数据备份、数据丢失问题,导致灾难发生后不能及时恢复从而出现更多的灾难事故。
应急响应:在灾难发生时,应急处理不力,不能快速定位原因或启动应急预案;协同问题等。
业务连续性管理:包括了组织和人员、流程和技术、业务影响分析、风险评估、业务连续性计划及应急预案、业务连续性资源建设、日常演练与测试、评估和持续改进等一系列工作,这本身就是一个很大的课题。
开发转运维问题:开发对运维不及时,导致运维还在开发手里,但是开发运维能力又不足;开发对运维的赋能不够,或者关键文档缺失等。
运维平台本身:监控不到位、可观测能力不够、自动化运维在需要灾备切换时切换失败等。
组织和人员问题:人员技能、意识问题;人员单点问题、值班排班不合理,例如在灾难发生时,关键人员不在岗等。
供应商问题:这里包含不合格的供应商,也包括供应商及其人员日常管理的问题。实际上,供应商人员和企业内部人员一样被纳入研发和运维、安全管理体系其实是非常困难的。
三、解决方案
对于IT基础设施和数字化产品的运维,保障高可用及业务连续性,是实施ITSM的首要价值。随着企业数字化转型的深入,企业对IT基础设施和数字化产品的可用性提出了更高的要求,基础设施和核心系统99.99%已经是一个基本要求(99.99%意味着一年只可以中断53分钟,平均到每月也就是4.38分钟)。为保障基础设施、核心及重要数字化系统的可用性,应对庞大且复杂的基础设施和数字化产品的运维工作,构建实施ITSM/ITIL项目和ITSM就显得非常必要。
企业可以围绕敏稳双态的思路优化运维流程,互联网企业,尤其是面向社会提供基础服务的企业或机构,在吸收SRE、DevOps的同时,还是要借助ITIL4、ISO20000来持续优化组织能力建设,夯实稳态的运维管理体系,尤其是对业务连续性贡献价值较大的事件管理、问题管理、变更发布管理、投产指挥、业务连续性管理等流程,完善以CMDB、ITSM、监控、自动化为核心的运维平台建设,其实提升业务连续性保障水平。
传统大中型企业,在数字化转型的旅程中,还需要同步构建数字化运营保障体系和平台。正如紫羚云创始人梁育刚先生的一个观点:“在古代兵法中就有“兵马未动,粮草先行”的行军作战原则,而今在数字中国建设和各行业数字化转型的征程中,企业都面临着核心系统全面升级的关键时刻(兵马动),数字化保障体系和保障平台没有提前优化或构建好(粮草先行),那对数字化转型升级往往会有灾难性的后果(很多企业认知误区就是先上核心系统,滞后建AITSM或ITSM)。这样在核心系统进行数字化转型建设和升级中没有数字化保障体系和平台进行“保驾护航”,而造成重大中断事件,影响IT连续性,进而影响到业务和企业”。

还没有实施ITSM的企业,可以在先解决有没有,再到好不好,最后实现以ITSM为中心,ITSM管理连接器+面向组件级管理的AIOps+面向服务管理组织级的AITSM的全面建设阶段完全的体系化、自动化和智能化运维管理。
ITSM项目作为一个管理项目,ITSM平台的有效落地,也被认为是科技部门运营管理变革的工作,建议具体以下面两种方式来推进:
第一种方式:以ITSM专业厂商顾问为指导,通过ITSM平台来引导团队理解专业厂商的设计和落地经验,从而短平快地落地ITSM;
第二种方式:以现有流程进行评审分析,统一内部流程认知为导向落地 ITSM 。
四、总结
IT基础设施和数字化产品的运维,也就是基础和系统运维层面,保障业务连续性是首要目标,而导致业务连续性事件的原因是各种各种的,需要优化运维组织,健全敏态和稳态相结合的运维管理流程,更需要实施ITSM项目。企业数字化转型,应该是企业的IT部门率先实现数字化转型,利用有效的数字化手段提升数字化管理水平,从而控制企业在生产经营过程中应用数字技术时面临的潜在风险,保障和提升业务连续性确保数字化转型目标的达成。ITSM对于保障数字化转型,提升数字化运营管理水平,保障业务连续性不是万能的,但是没有ITSM是万万不能的。可以实施ITSM为抓手,来导入ITIL4,构建数字化运营的组织能力、流程能力,构建数字化运营管理平台。