2023-08-01 09:43:44 极客网讯
随着大模型的走进公众视野,为AI领域带来了前所未有的机遇,大家期待着通过生成式AI能够解决更为复杂的问题,实现更高层次的智能。近期,Llama 2 发布的消息更是在AI圈引起了巨大轰动。

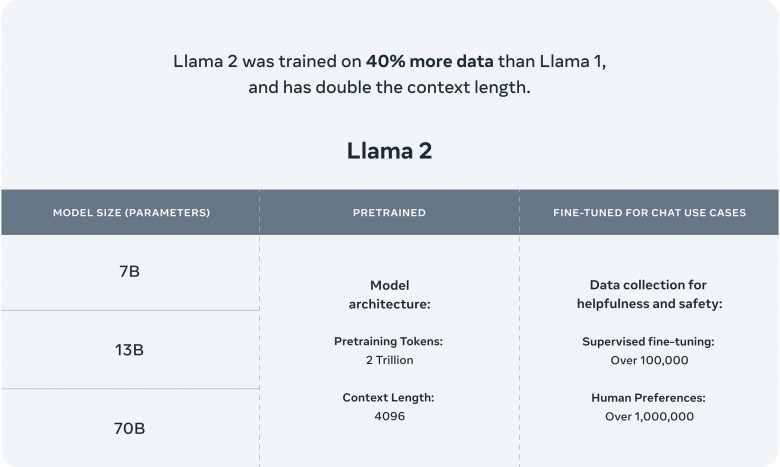
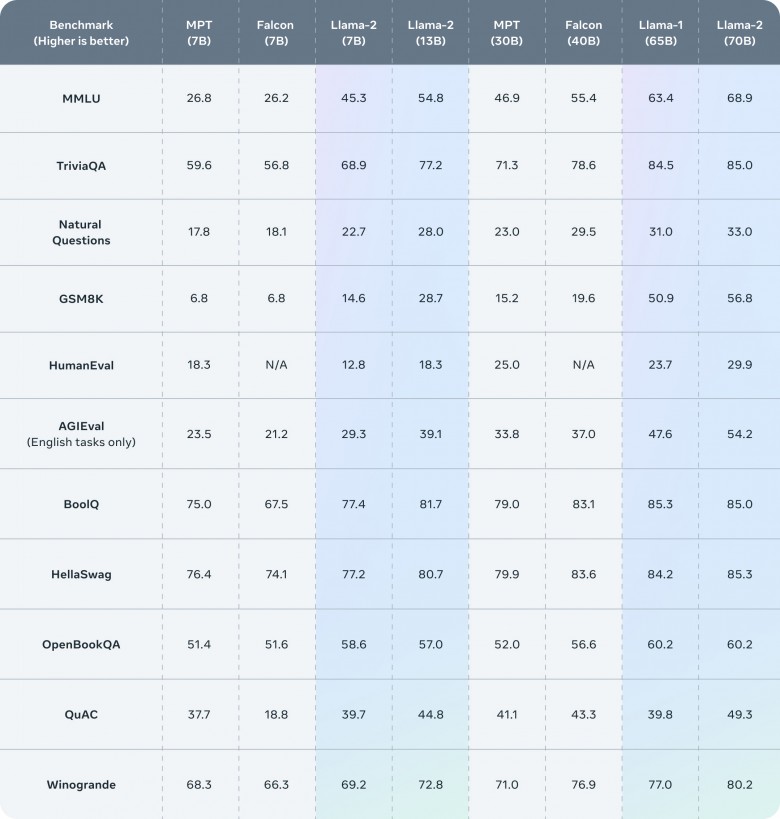
据公开资料显示,Llama 2在数据层面,相比上一代不仅使用了更多的训练数据,而且context length翻倍,达到4096。值得一提的是,Llama 2在公开测试基准上的结果显示,其在代码、常识推理、世界知识、阅读理解、数学等评测维度的能力均获得大幅提升。7B版本在很多测试集上接近甚至有超越30B的MPT模型的表现。
在 Llama 2 官网公布的50余家合作伙伴中,作为唯一的中国企业,海天瑞声榜上有名,成为 Llama 2 全球合作伙伴。同时,海天瑞声COO李科及CTO黄宇凯作为 Supporter,支持 Meta AI 的这种开源行为。可以让每个人都能从这个技术中受益良多,并为技术带来足够的透明度、审慎性和可信性。
当前在中文对话领域,公开的数据集往往量少、分布有偏、价格昂贵甚至不能商用。导致一些大模型在中文对话方面的能力,相比英文对话略逊一筹。尤其是在一些需要比较深的中文语言理解能力的对话场景,无论开源的还是闭源的大模型,都往往表现不佳。
海天瑞声正式推出「中文千万轮对话语料库DOTS-NLP-216」。真实场景采集,符合中文表达习惯的自然对话数据,将为中文大语言模型(LLM)带来新动能。我们致力于在安全合规的基础上,为大模型提供更好的性能和鲁棒性,帮助企业更轻松的构建高质量生成式AI应用。

数据集优势:
·中文多轮对话:符合中文表达习惯,真实场景采集的自然对话
·超大规模:上亿级 token
·立等可取:成品数据集
·自有版权:安全合规,可授权商用
数据集详情:
这是一个符合中国人表达习惯的自然对话数据集,共计约1,0000,000轮,上亿级token,包含正式&非正式风格对话,使用偏口语化自然表达。覆盖工作、生活、校园等场景,及金融、教育、娱乐、体育、汽车、科技等领域。
在数据集构成上,DOTS-NLP-216包含了对真实场景的对话采集,及高度还原真实场景的模拟对话这两种方式,兼顾分布的代表性、多样性和样本规模。
样例:

据悉,海天瑞声近期还发布了再融资预案,将建设不少于10大类型的大模型数据集系列产品,用于大语言模型、多模态大模型的训练和大模型评测。