2026-06-10 14:50:12 搜狐
数据采集与治理已经成为制约具身智能产业发展的瓶颈。相比大语言模型训练能使用万亿级别数据,具身智能所需的数据需要从真实物理环境采集,面临采集难、采集贵、数据可用性低和难以跨本体迁移等问题。建立高效可复用的数据采集机制、开放共建高质量的数据集,已经成为产业的当务之急。
近日,自变量机器人开源 XRZero-G0 ,论文发布当周即冲上alphaXiv趋势热榜前十,引发行业广泛关注。这是一套软硬一体的全身无本体数据采集与训练系统,它通过在硬件层添加头部视角,在软件层多视角交叉约束、添加限位和真机成功率检测,搭建起一套科学高效的数据采集和治理体系。
不仅如此,自变量还构建并开放了2000多小时、覆盖3000个任务的多模态全身无本体数据集 G0-Dataset ,并通过实验证实:以10:1比例混合无本体数据:真机数据,即可达到同等规模纯真机数据的效果。用这些数据训练的模型,摆脱了对固定本体姿态、特定本体型号的过拟合,具备出色的零样本迁移能力。
这也是国内首个大规模跑通“全身无本体采集→自动质检→混合训练→真机评测”全闭环的工作,搭建起一条规模化采集具身数据、形成迭代飞轮的可行之路。

XRZero-G0 整合无本体数据采集、闭环质检和数据配比方案
软硬一体保证数据高可用,有效率提升至85%以上
XRZero-G0 首先在硬件上添加了头部摄像头,将数据与腕部的两个视角严格对齐。同样的采集数据量,训练模型时的效率更高、混合收益更稳定。在软件上,XRZero-G0则将对数据质量的管控,引入了数据采集阶段,建立起三层递进的自动质检和筛选机制,而非等到训练时再优化:
1、在观测层,利用多个视角、多个时间的数据反复交叉验证,防止视觉与运动的误差不断放大。
2、在动力学层,将外部动作数据翻译成目标机器人自己能做的动作,避免机器人做动作时碰撞自己、超出关节限位,或是超出电机力矩。让数据筛选从“定性”变成100%可验证的步骤。
3、在策略层,用真机开放回环执行任务的成功率,来作为数据是否可用的最终判别依据。
这套方法论将数据治理从“采集端的工艺优化”延伸到“训练端的分布对齐”,将入库数据的有效率提升到85%以上,使得无本体数据也能达到与真机数据相当的可信和可执行水平。未来,它将成为以全身无本体数据为基础的预训练新范式。
发明“真机:无本体”数据“黄金配比”,数据成本降低至1/20
在具身智能领域,普遍会将真机数据与无本体数据混合,喂给模型训练。这能同时解决“真机数据少、采集昂贵”和“无本体数据泛化性差”的问题。但两者该以什么比例混合,过去一直没有科学的定论。自变量通过在后训练阶段进行对照实验,得出了一个可复现的科学配比:
10份无本体数据 + 1份真机数据的效果 = 同等规模的纯真机数据
简单来说,无本体数据能让模型见多识广、学会常识和动作规划;真机数据则能帮模型“查漏补缺”电机延迟、本体差异、摩擦力这些物理信息。两者结合,能将获取训练所需数据的成本降低到原有的1/20。
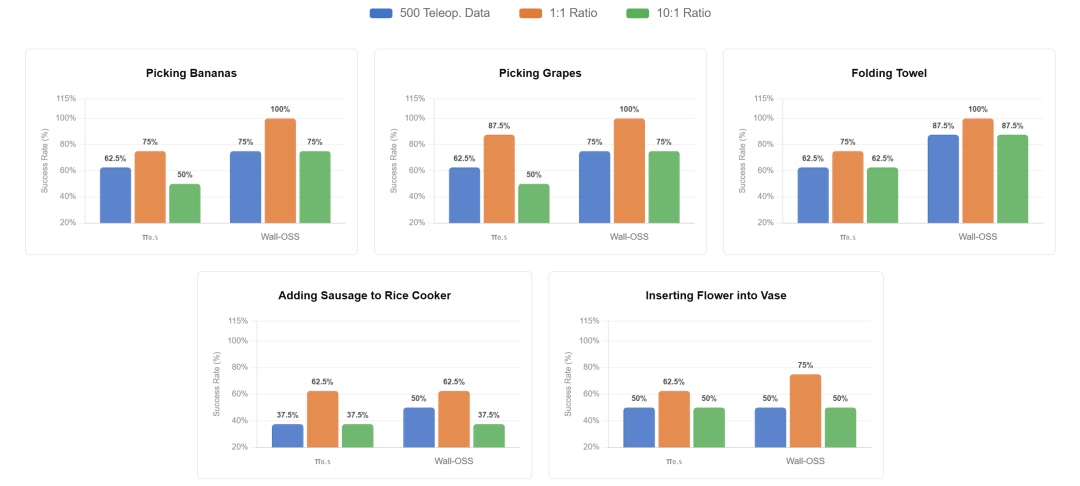
数据配比方案效果实测
不仅如此,自变量还将训练出的模型效果做了真机试验。自变量发现,相比于真机纯遥操数据,这种“混合配方”在两方面取得了更好的效果:首先是摆脱了对固定本体姿态的过拟合,能适应各种工作台角度、站位和视角,不依赖于特定采集环境。其次是具备了跨本体的零样本迁移能力,可以在完全没有参与采集的机器人本体上零样本部署,无需针对性微调。
这些真机实验证明:自变量构建的这一整套数据采集和治理方法,以及将真机和无本体数据混合用于训练的方式,能够支撑具身模型训练走向规模化,并非“权宜之计”,而是科学的系统化的路径。
开放首批无本体数据集,构建具身行业数据基础设施
真实物理环境的数据已经成为具身智能模型发展的“珍贵养料”。很多具身智能企业和三方公司也纷纷开始自建数据采集流程,摸索可行的路径。自变量作为在具身数据采集方面的先行者,决定打破数据孤岛、促进整个行业的数据基建:将 XRZero-G0 的核心成果全面开源。
目前,自变量采集构建的首批无本体数据集已经在 Huggingface 平台上线,方便全球开发者开箱即用。相关的技术报告也发布在 arXiv 等平台,涵盖硬件搭建、自动化质检流水线和混合数据配比后训练策略等方面,让具身智能产业能够复现使用。相关论文和数据集的发表,也在arXiv相关论坛alphaXiv和国内社区引发广泛的讨论和关注。
未来,自变量期待与全球科研力量并肩同行,彻底告别“盲采盲训”的摸索阶段,共同见证通用机器人融入物理世界的黎明到来。