2025-10-20 15:16:53 中华网
在过去,训练一款高性能视觉大模型,往往需要承担高昂成本与复杂工程压力。9 月底,灵感实验室与 LMMs-Lab 联合推出的 LLaVA-OneVision-1.5 彻底改写了这一现状。

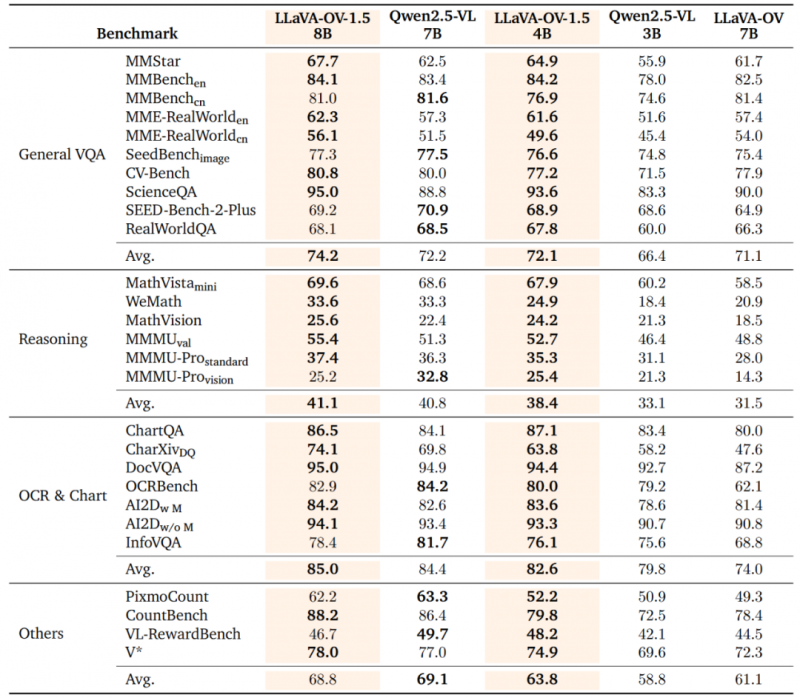
这款具备视觉理解、图文对话能力的 8B 规模多模态模型,仅用 128 张A800 GPU4 天时间便完成预训练,且在公开基准测试中性能媲美顶级大模型,印证了「非堆量式」性能提升的技术价值。
这一突破的背后,不仅有百度百舸 AI 计算平台的高性能 AI 基础设施支撑,更有平台内置的 AIAK 训练框架提供的极致工程提效能力——从适配主流模型架构到多维度的分布式训练加速优化,共同构成模型高效落地的关键保障。
更值得行业关注的是,LLaVA-OneVision-1.5 打破了传统开源「仅放权重」的核心局限。传统模式下,仅开放模型权重相当于给开发者「成品黑箱」:既看不到训练数据的来源与筛选逻辑,也不清楚超参设置、并行策略等关键配置,更没有数据清洗、评测验证的流程参考,开发者只能「拿来用」,难以根据自身需求优化迭代,甚至无法复现模型性能,中小团队想基于此创新更是无从下手。
而作为业界首批实现「全流程开源」的多模态模型之一,LLaVA-OneVision-1.5 完整开放了 85M 预训练 + 22M 指令的全场景数据、超参与并行策略等训练配置、数据清洗与评测日志等优化细节,更提供一键跑通的复现路径。
这种开放模式让研究者、企业、高校团队可直接重构、验证与扩展模型,真正推动多模态 AI 从「巨头专属」变为全行业可复用、可创新的公共资产。

1. LLaVA-OneVision-1.5:以高性能 + 低成本突破,全流程开源推动多模态 AI 普惠化
LLaVA-OneVision-1.5 的领先性,不仅体现在性能指标上,更在于它以高质量的数据、简洁高效的模型架构、紧凑的训练策略与极致的工程优化,构建出高性能 + 低成本的多模态模型新范式,全流程开源更放大其普惠价值。
高质量数据:兼顾覆盖、均衡与任务泛化
构建 85M 预训练数据 + 22M 指令数据矩阵,融合 8 大异构来源覆盖图像、文档、OCR、数理推理等场景;通过概念均衡采样补充稀有概念、剔除噪声,避免模型偏科,确保跨模态任务泛化能力。
目前,这两类核心数据集已随开源同步开放,开发者无需重新采集标注,可直接用于模型训练或优化迭代,省去传统仅开放权重模式下无数据可用的核心痛点。
简洁高效的模型架构:自研 RICE-ViT视觉编码器兼顾细节感知与训练效率
自研 RICE-ViT 视觉编码器,精准捕捉表格单元格、文档小字等细粒度信息;搭配轻量化视觉 - 语言对齐层,简化跨模态融合链路,既保证看得清,又降低训练负载,实现感知精度与效率双优。
该架构的设计细节、代码实现已纳入开源包,不同于传统仅开放权重下架构细节模糊的问题,即使是中小团队,也能基于此快速搭建多模态模型基础框架,无需从零研发复杂结构。
紧凑的三阶段训练策略:让模型高效成长
采用「图文基础对齐-均衡知识注入-指令实战强化」三阶段训练,目标明确无冗余迭代,加速模型从「看懂」到「会用」的能力成长,为低成本训练奠定基础。
训练阶段的超参设置、任务划分、迭代节奏等关键信息,已通过开源脚本完整记录 —— 对比传统仅开放权重下, 训练过程不可追溯的局限,开发者可按步骤复现训练过程,甚至根据自身需求微调策略,大幅缩短研发周期。
极致的工程优化:以效率提升实现成本突破
通过离线数据打包(11 倍 padding 压缩)、混合并行训练策略等优化算力分配,128 张 A800 GPU 仅用 4 天完成 8B 模型预训练,印证了算法与工程协同,高性能与低成本可兼得。
而实现这一优化的核心工具(如数据打包脚本、并行策略配置文件)均已开源,区别于传统仅开放权重下,工程优化经验无法复用的问题,开发者可直接复用这套工程方案,在自有算力资源上实现效率跃升,无需重复投入精力攻克工程难题。
2. 百度百舸 AI 计算平台:为极致效率提供底层动力
LLaVA-OneVision-1.5 的突破,离不开百度百舸从「高性能 AI 基础设施」到 「极致工程提效」的全栈支撑,为大模型提供了从算力基础设施到训练系统的端到端能力,帮助团队在有限预算下实现极致效率。
高性能基础设施:为大模型训练提供稳定底座
LLaVA-OneVision-1.5 的训练依托于百舸平台提供的 GPU 计算集群。在 128 张 A800 GPU 的分布式环境下,百舸通过高带宽互联架构与弹性调度系统,实现了算力利用率与吞吐率的最大化,让 8B 规模模型在 4 天内完成 85M 样本全参数训练成为现实。
全链路工程提效:AIAK 训练框架加速多模态大模型任务
在模型训练层面,LLaVA-OneVision-1.5 研发团队深度依托百度百舸平台提供的 AIAK-Training-LLM 训练框架。该框架全面支持多模态模型在不同训练阶段的需求,通过 混合并行策略、通信计算重叠(communication overlap)、数据打包(data packing)等加速技术,全方位提升了训练过程的流畅性与资源利用效率。得益于此,LLaVA-OneVision-1.5 的训练效率实现数倍提升,训练成本大幅降低,为模型的快速迭代奠定了坚实基础。
AIAK-Training-LLM 基于 Megatron 打造,是百度百舸为大模型训练场景量身定制的 AI 加速工具,致力于帮助开发者高效开展大规模分布式训练,显著提升训练性能与资源利用率。
AIAK 目前已全面支持主流模型场景的预训练与微调,涵盖大语言模型、多模态理解模型、视频生成模型等,兼容包括 Qwen 系列、LLaMA 系列、DeepSeek 系列、QwenVL、InternVL、QianfanVL、LLaVA-OneVision(LLaVAOV)、Wan 系列等在内的主流开源模型。不仅如此,用户也可基于 AIAK 灵活构建自定义模型架构,并高效开展训练任务。
在性能层面,AIAK 针对不同模型结构进行了深度优化,提供覆盖混合并行策略、通信计算重叠(communication overlap)、高性价比显存管理、FP8 低精度训练、算子融合、高性能优化器等在内的多项关键技术,各类模型 MFU(Model FLOPs Utilization)平均提升 30%,实现业界领先的训练性能。
AIAK 已深度集成于百度百舸平台,用户可直接通过平台获取预置训练镜像。同时,围绕 LLaVA-OneVision-1.5 的完整训练代码与配置已全面开源,未来还将持续开放更多工具链与优化能力,进一步降低大模型的研发门槛。
3. 让每个团队都能打造属于自己的 AI 模型
LLaVA-OneVision-1.5 的成功,直观体现了百度百舸的「快稳省」的核心价值——不仅提供高性能 AI 基础设施筑牢算力底座,更以极致工程提效能力为客户打通「数据处理 - 模型训练 - 效率调优」全流程,大幅缩短训练周期、降低研发成本。
如今,无论是资源有限的研究机构、追求效率的企业团队,还是探索创新的初创开发者,都能在百舸平台轻松开启 AI 模型研发:快速搭建高性能训练环境,借助 AIAK 工具链实现多模态训练加速,更可复用 LLaVA-OneVision-1.5 的开源方案,在可控成本下迭代出贴合自身业务场景的专属 AI 模型。