2023-08-05 11:31:26 西盟科技资讯
它就是由 Zilliz 原厂打造的可提供全托管的向量数据库云服务产品—— Zilliz Cloud。此前,大家已经对 Zilliz Cloud 升级版本的诸多实用新特性有所了解,例如dynamic schema、partition key、支持更多样的集群类型等。与此同时,Zilliz Cloud 还采用了全新的定价策略,旨在以更经济实惠的价格提高更高质量的服务。
不过,Zilliz Cloud 最为人称道的还要数它的性能,其向量检索速度比 Milvus 要快 3-6 倍。今天,我们将从性能方面全面拆解 Zilliz Cloud。

Zilliz Cloud 有多快?
想要回答这个问题,首先需要明确定义使用场景和参照对比的产品。
明确完这两点后,便需要借助工具来进行性能测试。这里,我们可以用开源的向量数据库性能测试工具——VectorDBBench来测速。VectorDBBench 支持多样的测试场景,允许用户通过直观的前端交互界面测试许多开源向量数据库或者云服务(如 Milvus、Zilliz Cloud 等),并通过直观的交互界面大大降低了性能测试的门槛。
以下是关于 Zilliz Cloud 的一些性能测试的对比结果:
●比 Milvus 快 6 倍
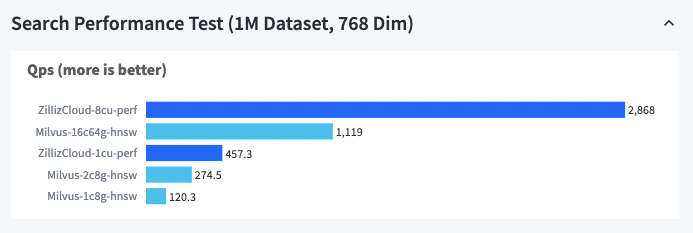
上图展示了在 100 万 768 维数据集上,使用不同资源配置的 Milvus 和不同 CU 大小的 Zilliz Cloud 的性能表现。从结果来看,Zilliz Cloud 的速度是 Milvus 的 3 倍。
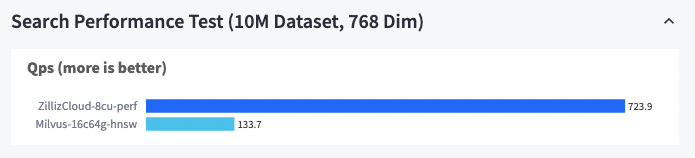
现在,我们进一步增加数据量,采用 1000 万 768 维数据集。Zilliz Cloud 同样展示了强劲的性能,QPS 是 Miluvs 的 6 倍。
●比其他开源向量数据库快 4-191 倍
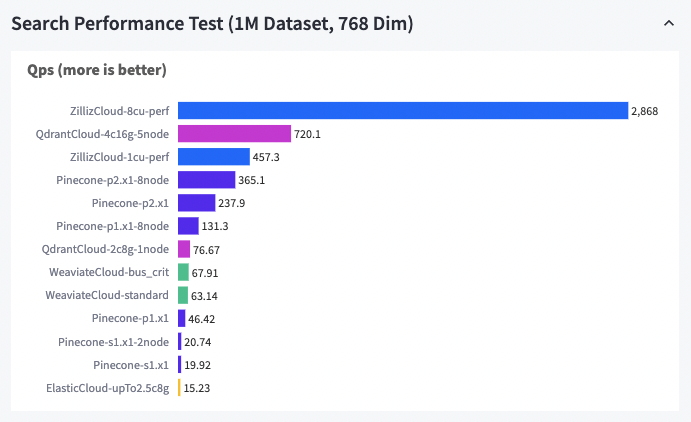
在与其他主流向量数据库的对比中,Zilliz Cloud 的性能也是一骑绝尘。根据性能测试结果,在 100 万 768 维数据集的条件下,Zilliz Cloud 的 QPS 是其他产品的 4 - 191 倍。
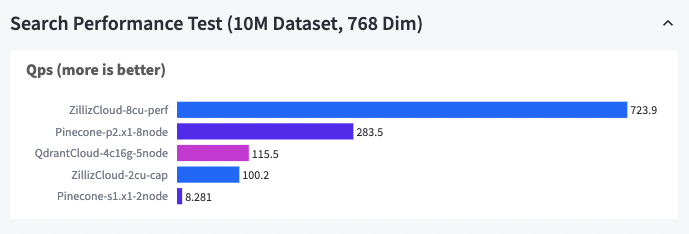
而在更大的数据集下,Zilliz Cloud 的表现同样亮眼。例如,Zilliz 的 QPS 是 Pinecone 和 Qdrant 的 3 倍左右。
Zilliz Cloud 为什么这么快?
Zilliz Cloud 为什么这么快?接下来让我们来一探究竟。
●强大的向量索引引擎
如大家所知,向量数据库是一种典型的计算量很大的应用,因此其中负责向量计算的向量检索算法会吃走绝大部分资源,并很大程度上决定了一个向量数据库的性能。
ANN-Benchmark 是业内最权威的向量检索算法性能测试工具,它可以展示不同算法在不同真实数据集下的表现。而 Milvus 集成的算法库 Knowhere 和来自 Zilliz Cloud 的 Glass,最近登顶霸榜了这份榜单。
Glass 是 Zilliz Cloud 在自研索引算法探索中的一个历史版本。作为向量数据库最核心的引擎,它亮眼的表现为 Zilliz Cloud 实现性能上的飞跃提供了重要支持。
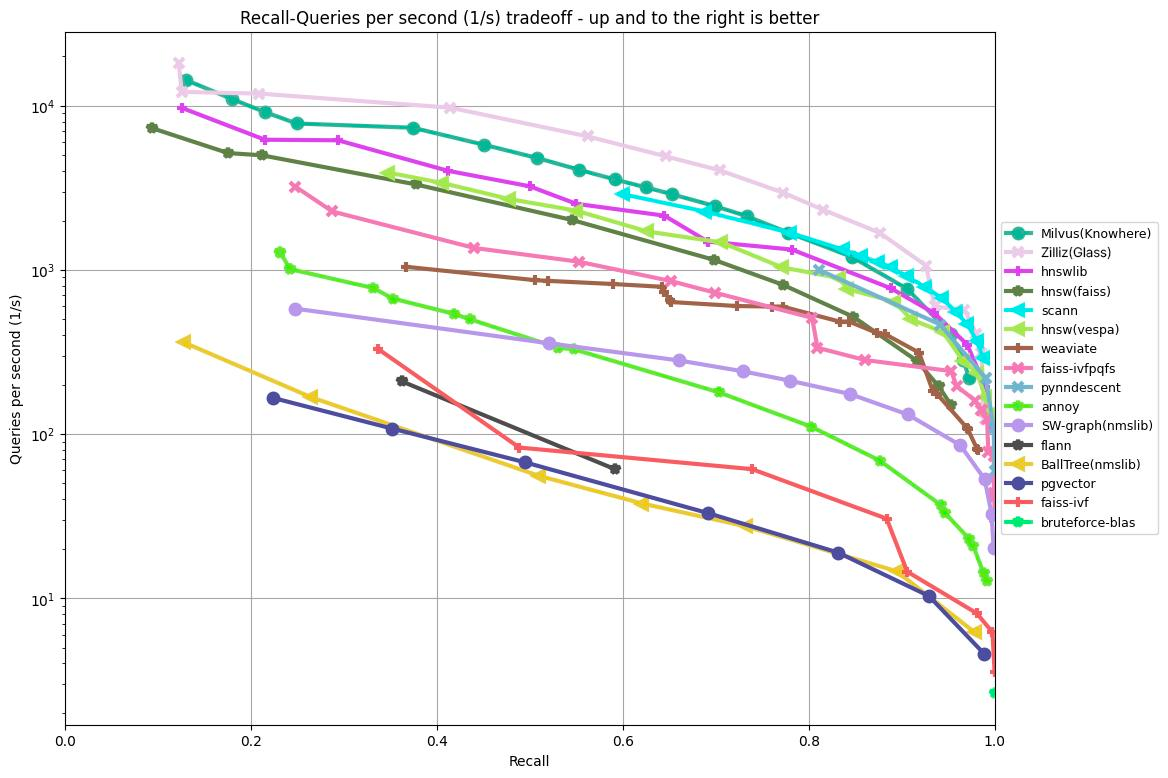
上图是来自ANN-Benchmark的最新向量检索算法性能测试结果,测试结果基于两个不同的数据集:
●gist-960-euclidean:100 万 960 维向量数据,使用欧式距离。
●fashion-mnist-784-euclidean: 6 万 784 维向量,使用欧式距离。
曲线越高意味着每秒算法可处理的查询越多。同样,曲线越向右延展意味着算法的召回率越高。
通过结果,我们可以看出,Glass(粉色曲线)的 QPS 和召回两个指标都位列榜首。因此,Zilliz Cloud 闪电般的向量检索速度,有一大部分可以归功于 Glass 索引引擎的出色表现。
●代码结构优化
除了强力的索引外,Zilliz Cloud 在之前版本的基础上进行了大量的代码结构的优化,包括对冗余查询链路的清理、查询合并逻辑的调度策略优化、并发策略优化和引入高效实现等。这些工作帮助 Zilliz Cloud 最大化地利用了其强大的索引算法能力,减少了开支。
同时,新版本的 Zilliz Cloud 还解决了一些出现性能问题的场景,比如过滤搜索等。
●高效的 AutoIndex
在讨论系统性能时,召回率是一个重要且不可忽视的话题。不够理想的召回率会使得检索结果无法满足需求,进而使检索行为失去其意义。然而,过高的召回率可能会极大牺牲性能。稳定的召回率能帮我们在性能和准确性之间找到平衡,使得结果可预测,从而更好地支持各类生产生活场景。
召回率受多种因素影响,包括数据集本身、建立索引的参数、查询参数、数据分布,甚至 topK 的大小等。因此,如何控制召回率,是一个复杂而重要的问题。大部分数据库系统为解决这一问题,通常会采用以下两种方案:
●让用户提供参数:这种方式灵活但使用门槛高。
●提供经验参数:这种方法易用但灵活性较差,对于不同的数据和 topK 等场景无法做到精细控制。
为了解决这个问题,Zilliz Cloud 的 AutoIndex 提供了一个既简便又灵活的解决方案:一方面可以基于模型对实际应用案例进行全方位分析,另一方面能为每次检索请求定制一套参数。这样一来,Zilliz Cloud 不仅能够实现稳定的召回率,而且还能确保优秀的性能,满足用户在实际应用中的需求。
总体而言,Zilliz Cloud 的升级版本无论从功能还是性能来说都有了里程碑式的提高,点击体验更加便捷高效的的全新向量数据库。未来,我们也会持续提升产品的性能、不断进步,欢迎大家持续关注!