2026-05-19 12:04:59 中华网

2026年5月19日,北京——最近,IBM研究院与英伟达(NVIDIA)、三星共同展示了一项内容感知存储系统(content awareness storage)。该系统在单台服务器上成功支持千亿级别向量的存储与检索,平均查询延迟为694毫秒,召回精度达90%。系统硬件组合为IBM Storage Scale System6000全闪存设备、六颗英伟达H200 GPU以及48块三星30.72TB容量的PCIe Gen5 NVMe固态硬盘。IBM Storage Scale System 6000 全闪存设备将计算与存储解耦,并通过英伟达 H200 GPU 加速索引重建,将原本基于 CPU 需耗时数小时的索引构建过程,缩短至 GPU 上的数分钟。
我们一起来看看IBM是如何用单机实现了现在大集群才能实现的结果。
今天,大模型版本平均数天便迎来一次更新,RAG(检索增强生成)已成为挖掘非结构化数据价值的核心。企业 CIO 普遍面临核心课题:如何借助通用人工智能(AI)与 AI 智能体实现日常运营提效?如何依托现有 IT 资源输出精准、高价值的业务决策?
高质量 AI 应答的核心前提,是模型可高效触达原始可信数据,而检索增强生成(RAG)正是优化推理效果、提升应答准确性与时效性的关键技术。然而,当向量数据量激增至数十亿级别时,CIO们面临到了传统全内存向量索引方案的容量与成本困境。飞涨的DRAM价格、不稳定的货期和数据在CPU与存储间频繁搬运造成的“内存墙”与“IO墙”瓶颈,正严重制约着AI应用的规模化落地,企业在落地过程中普遍遭遇四大痛点:
·非结构化数据类型繁杂,仅1%数据能被 AI 有效利用并创造价值;
·数据失真与模型幻觉为企业带来合规与决策风险;
·RAG 流程引发多副本冗余、数据反复传输,成本居高不下;
·面向 PB 级海量数据时,传统架构性能瓶颈凸显,难以规模化落地。
打破 “1% 数据困局”,让 AI 走向数据
当下企业被海量非结构化数据包围,PDF、邮件、音视频、演示文稿、财务报表等数据持续增长,但能被大模型调用并产生价值的占比不足 1%。
RAG 技术通过数据向量化、优化批量刷新周期、依托 GPU 集群实现分布式处理,可打破数据访问限制,让 AI 覆盖更广泛的数据来源。而 IBM Storage Scale 的核心突破,在于摒弃 “数据迁移至 AI” 的传统模式,实现 “AI 走向数据” 的全新范式。简单的说,就是CAS技术直接在存储层做文档的提取和向量化(甚至集成了NVIDIA的微服务)实现了让 AI 走向数据,即让 AI 快速定位合规、洁净的可用数据,从源头降低模型幻觉风险,这一能力依托 IBMCAS 内容感知存储(Content-Aware Storage)技术实现。
AI 存储新范式:CAS 将向量处理下沉至存储层
CAS 的颠覆性创新,是让存储系统从被动“数据仓库”转变为主动“AI 参与单元”—— 存储不再仅保存数据,而是对数据项进行量化理解,将原本由向量数据库承担的文档向量化流程,从应用层直接下沉至存储层。

通俗来讲,传统 RAG 需先将数据从存储取出,在外部完成向量化后导入向量数据库;而 CAS 可在存储系统内部完成全流程处理,数据无需迁移、无需拷贝。
该技术源于 IBM 研究院在自然语言处理、向量嵌入模型、硬件加速领域的长期技术积累。文档数据提取流程深度整合基于 NVIDIA NIM 构建的 NVIDIA NeMo Retriever 微服务(隶属于 NVIDIA AI Enterprise),确保 AI 助手与 AI Agent 基于最新、最相关的上下文应答,简化 RAG 运维、提升 AI 应用业务价值。
IBM Storage Scale(原 GPFS)为企业构建全局统一数据平台,在多站点、多云、数据中心与边缘环境间打造单一命名空间,兼容第三方存储,打破数据孤岛,实现全域数据统一访问。CAS 作为 Storage Scale 的全新 AI 增强能力,助力企业从现有数据资产中挖掘更大价值,显著提升 RAG 准确性、减少模型幻觉,让 AI 模型无需重新训练即可同步最新数据,适配科研、客户服务、知识型应用等企业级场景。
企业级 RAG 规模化:打破性能瓶颈,加码安全合规
市面主流向量数据库支撑百亿级向量,通常需要数十乃至上百台服务器,节点规模扩张后,分布式索引同步、故障恢复、扩容迁移等问题频发,运维与成本压力巨大。
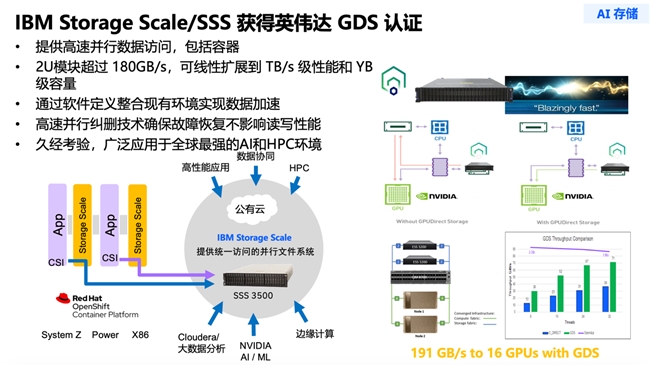
IBM Storage Scale 存储方案实现单服务器承载 1000 亿向量,按企业典型文档场景测算,可全面覆盖 PB 级至数十 PB 级非结构化数据,为企业 CIO 带来四大核心价值:
1.基础设施成本指数级下降:无需部署数十乃至上百台向量数据库服务器;
2.运维复杂度大幅降低:单一存储集群即可支撑全流程 RAG 需求;
3.企业级实时性保障:端到端延迟低至694 毫秒,满足核心业务实时要求;
4.数据安全能力强化:继承原始数据源权限管控体系,聊天机器人应答等衍生数据统一遵循安全策略。
底层核心优势:数据就地处理、无需迁移,检索与计算在数据存储位置直接完成,天然契合数据合规与安全管控要求。
单服务器承载千亿向量的技术底气:核心依托IBM Storage Scale System 6000 全闪存存储一体机:单节点配置 48 块 NVMe 盘,搭载 PCIe Gen5 与 400Gb InfiniBand 高速互联,结合 NVIDIA GPUDirect Storage 技术,实现 GPU 直接访问 SSD 数据,跳过 CPU 数据搬运环节。
系统将超大规模索引拆分为多个独立子索引,各子索引可独立优化、独立重建、互不干扰,彻底解决传统向量数据库 “牵一发而动全身” 的重构痛点。
实测数据对比:纯 CPU 环境下,千亿级向量索引重建需 120 天;搭载 6 块 NVIDIA H200 GPU 的 IBM Storage Scale System 6000,仅需4 天即可完成。
结语
人工智能时代,存储的角色被重新定义。IBM 给出明确答案:存储不应成为 AI 瓶颈,而应是 AI 基础设施的核心加速器。
本次方案提供纯软件版与一体机版两种交付形态,全面兼容 RHEL AI 开源数据流水线,深度集成 NVIDIA AI Data Platform,是可直接落地生产环境的企业级解决方案。
以 IBM Storage Scale 为核心的 AI 存储方案,正在让 PB 级企业 RAG 从技术构想变为现实。RAG 的规模上限,不再受限于向量数量与存储性能,而取决于企业可触达、可利用的数据边界。(作者:金鑫,IBM中国区存储业务销售总经理)
关于IBM
IBM 是全球领先的混合云、人工智能及企业服务提供商,帮助超过 175 个国家和地区的客户,从其拥有的数据中获取商业洞察,简化业务流程,降低成本,并获得行业竞争优势。金融服务、电信和医疗健康等关键基础设施领域的超过 4000 家政府和企业实体依靠 IBM 混合云平台和红帽 OpenShift 快速、高效、安全地实现数字化转型。IBM 在人工智能、量子计算、行业云解决方案和企业服务方面的突破性创新为我们的客户提供了开放和灵活的选择。对企业诚信、透明治理、社会责任、包容文化和服务精神的长期承诺是 IBM 业务发展的基石。