2026-05-16 16:03:23 西盟科技资讯

近日,北京人形机器人创新中心(以下简称“北京人形”)在WorldArena全球权威评测中连下两城——继WoW具身世界模型登顶World Arena Data Engine(数据引擎)赛道后,首个“具身大一统”模型Pelican-Unify 1.0 在World Arena综合评测中再度登顶。北京人形由此成为全球唯一在WorldArena两大核心赛道同时夺冠的企业,加冕具身智能领域首个"双冠王",具身大脑能力跻身世界第一梯队。
Pelican-Unify 1.0,作为通用具身智能平台“慧思开物”的重要组成部分,该模型在理解、推理、想象、行动等维度同时达到全球顶尖水平,世界模型各项能力尤为突出,并登顶World Arena权威榜单。这标志着具身智能从“功能拼凑”迈入了“协同进化”的新阶段,为迈向通用具身智能奠定了坚实的技术与路径基础。

顶流同台竞技,在最严苛的“试金石”中脱颖而出
WorldArena 由清华大学联合普林斯顿大学、新加坡国立大学、北京大学、中国香港大学、中国科学院、上海交通大学、中国科学技术大学等8所顶尖机构共同发起,涵盖6大评测维度 + 16项细分指标 + 3大真实应用任务。因其学术严谨性与行业公信力,吸引了全球几乎所有头部世界模型团队参评,在激烈角逐中,Pelican Unify 1.0凭借硬核技术实力脱颖而出,登顶World Arena。
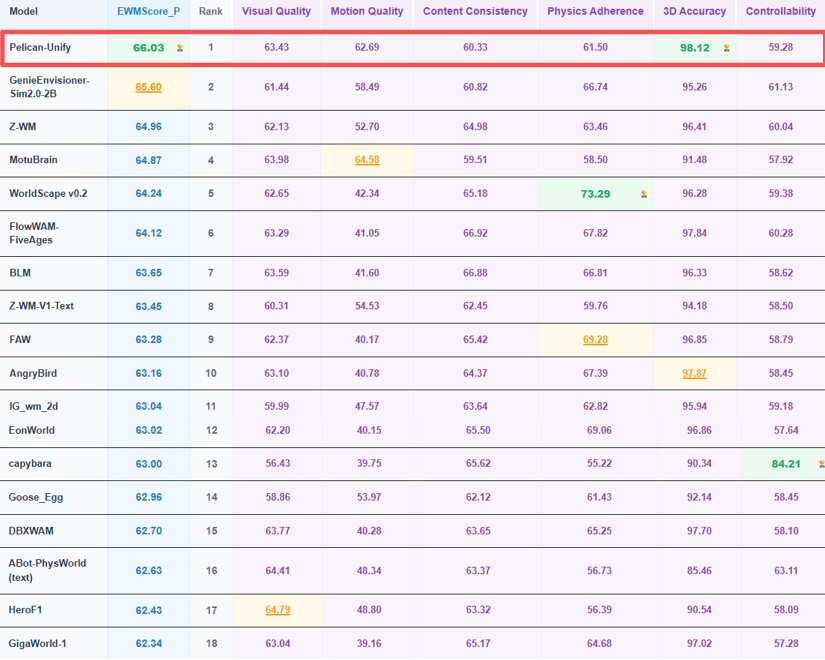
Pelican-Unify 1.0在 World Arena 登顶并非偏科取胜,同时展现了极强的综合素质。具体表现如下:
①EWM Score(综合得分)稳居榜首:包括视觉质量、运动质量、内容一致性、物理遵循、3D准确性等多维度的极其严苛的整体评估中,Pelican-Unify 1.0拿下了综合第一,各项能力完美平衡,能够全方位支撑复杂的具身长程任务。
②3D Accuracy接近满分:具身智能离不开对三维空间结构的理解,通过深度估计误差与透视一致性,Pelican-Unify 1.0已接近满分的表现充分验证了对场景空间几何关系的理解与构建。
第三方权威榜单验证,具身智能迎来“大一统”模型爆点
过去,具身智能沿着多条路线快速发展:VLM 擅长理解图像和指令,VLA 能够将视觉语言输入映射为动作,世界模型能够预测未来状态。但这些路线往往各自优化、分段连接,容易形成“看、想、动”之间的断裂:理解不能直接被行动验证,行动缺少未来后果约束,世界想象也难以被语言推理稳定引导。
Pelican-Unify 1.0 的核心思路是:理解、推理、想象与行动不应是四个孤立模块,而应是同一个物理智能回路的不同侧面,具体实现三类统一:
①统一理解:将场景、指令、视觉上下文和动作历史映射到共享语义空间;
②统一推理:将任务意图、动作选择和未来后果转化为可监督的语言化推理过程;
③统一生成:在同一个扩散解码过程中联合生成未来视频和低层动作,使动作受到想象后果塑造,想象受到任务推理约束。
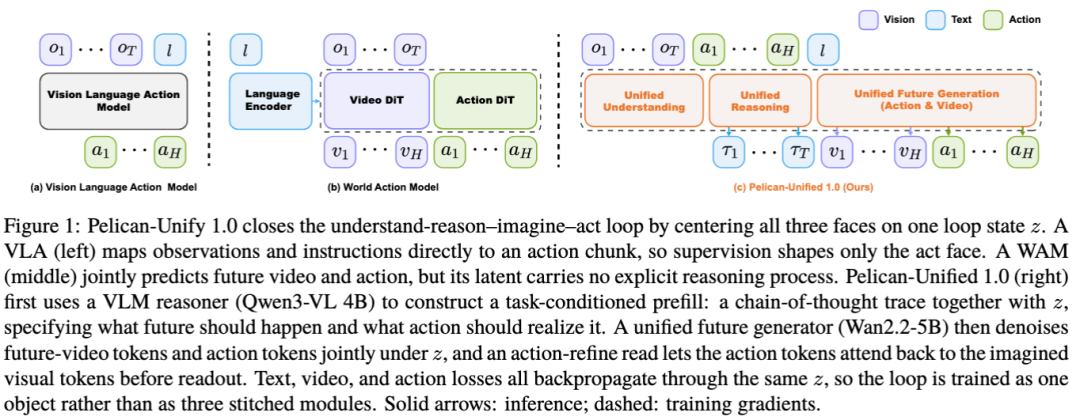
从模型结构上看,Pelican-Unify 1.0 由两部分紧密耦合:上层是 VLM 统一理解器与推理器,基于场景、指令、视觉上下文和动作历史构建任务状态,并生成面向任务、动作与未来后果的 Chain-of-thought(思路链);下层是 Unify Future Generator(统一未来生成器),以同一个 latent z 为条件,在统一扩散过程中联合生成未来视频和动作 chunk。
latent z 不是简单的模块接口,而是整个物理认知闭环的关键状态。文本、视频和动作三路损失都会反传到同一个共享表示中,使模型在训练中同时学习“如何理解任务”“未来会发生什么”以及“应该执行什么动作”。因此,Pelican-Unify 1.0 不是把 VLM、世界模型和动作策略串起来,而是让它们在同一个训练目标下相互约束、共同演化。
机器人“先想象,再行动”,真机验证闭环智能的实际价值
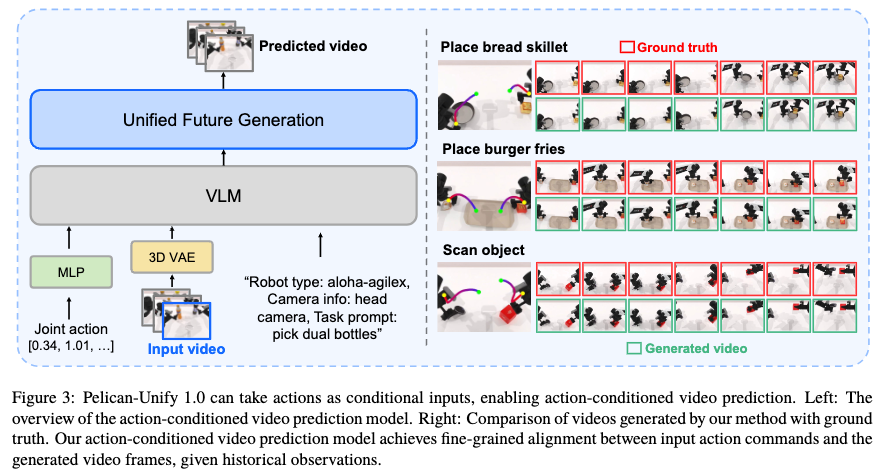
Pelican-Unify 1.0 的关键能力,是能够在动作执行前生成未来视觉状态,并让动作预测与未来想象相互对齐,模型接收历史观测和动作条件后,可以预测对应未来视频,使动作命令与生成帧之间保持细粒度一致。
这意味着,Pelican-Unify 1.0 的“想象”不是脱离执行的视觉生成,而是服务于机器人行动的未来预演。动作不再只是从图像和语言直接回归出来,而是在同一个生成过程中与未来状态共同建模:未来画面约束动作是否合理,动作轨迹也约束未来是否可达。对于复杂操作任务,这种机制能够帮助模型更好地处理长程依赖、物体接触、遮挡和空间变化。
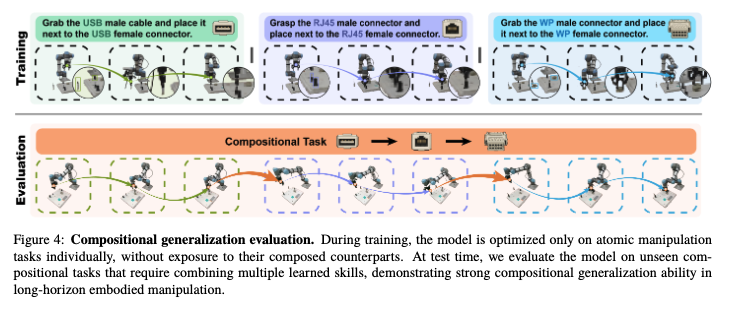
真实机器人是检验“推理—想象—行动”闭环的真正考场。北京人形将 Pelican Unify 1.0 部署至天工人形机器人及UR5e 机械臂上,重点验证组合泛化与零样本迁移。在组合泛化实验中,模型仅用“插入 RJ45 接头”和“做防水处理”等原子任务训练数据,未见过完整组合演示。测试中,机器人需依自然语言指令先插线、后防水,跨阶段保持任务目标并基于前序结果规划下一步,Pelican Unify 1.0 成功完成了这类未见过的长程组合任务。
统一不是折中:第三方评测平台权威验证单项能力
统一模型最容易被质疑的一点是:把多种能力放进一个模型,会不会导致每项能力都变弱?Pelican-Unify 1.0 的实验结果给出了答案。
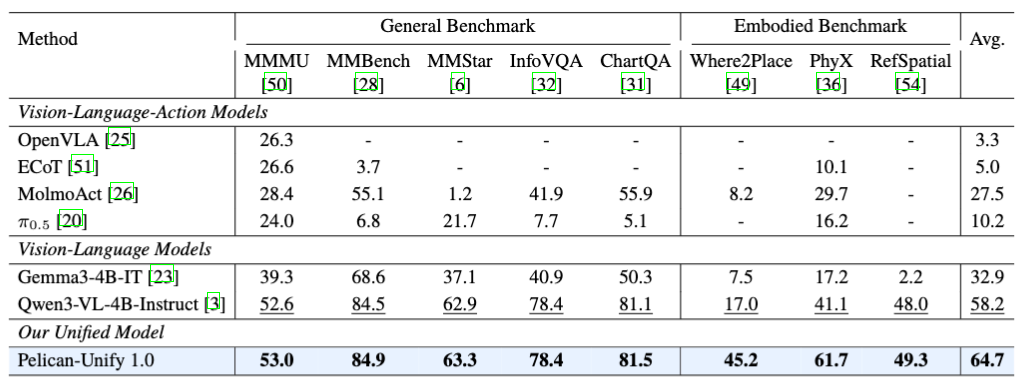
在统一的理解和推理能力上达到了同级别模型第一。在 VLM 评测中,Pelican-Unify 1.0 在 8 个 General / Embodied Benchmarks 上取得 64.7 平均分,均达到SOTA水平,并在更具具身属性的 Where2Place 和 PhyX 上相比基座模型分别提升28.2和20.6分,证明统一训练并没有削弱通用多模态能力,反而增强了空间理解、物理理解和行动相关语义。
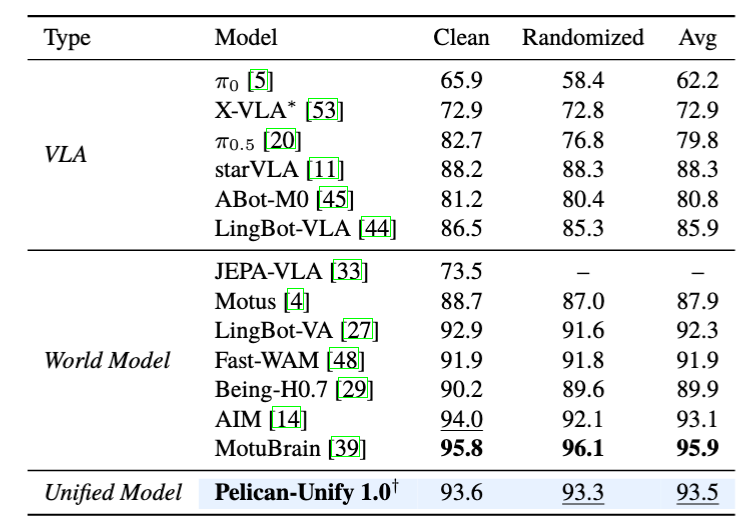
在统一的动作生成能力方面,整体性能和最佳模型性能相当。Pelican-Unify 1.0 在 RoboTwin 50-task dual-arm benchmark 上取得93.5%平均成功率,其中50 个任务中有 31 个任务成功率达到至少 95%,15 个任务达到 100%,覆盖插拔、堆叠、交接等不同类型任务,跟当前SOTA模型性能基本持平,证明具身大一统模型具备强动作执行能力。
迈向通用具身智能的新范式
Pelican-Unify 1.0 登顶的意义并不只是拿到某一个榜单第一,而是提出了一条更接近通用具身智能的建模路径:不再把理解、推理、想象与行动视作独立模块分别优化,再通过工程方式拼接;而是从一开始就让它们共享表示、共同训练、相互塑形。
这一路线的价值在于,它让模型既能保持专家能力,又能在真实任务中形成更完整的闭环智能。机器人可以理解目标与场景,推理过程让任务意图变得可监督,未来想象让动作具备后果意识,而动作执行又反过来检验理解和想象是否可靠。Pelican-Unify 1.0 表明,具身智能的下一阶段,可能不只是更大的视觉模型、更强的动作策略或更逼真的世界模型,而是一个能够把“看见、思考、想象、行动”统一起来的自适应系统。
Pelican-Unify 1.0的研发主体——北京人形机器人创新中心,以通用机器人平台"具身天工"和通用具身智能平台"慧思开物"为双核心,构建起覆盖"本体—大脑—小脑—平台—生态"的全栈式闭环体系,让顶尖的模型融入真实的生产与服务场景,释放其真正的价值。具身智能下一阶段的关键词,是形成更完整的闭环和大脑各部分能力的协同进化——而北京人形凭借"双冠王"的技术积累,降低具身智能的进入门槛,加速人形机器人从专用设备向通用生产力工具的演进。
论文地址:https://arxiv.org/pdf/2605.15153