2026-02-10 13:02:24 西盟科技资讯
过去一年,生成式人工智能在音乐行业的应用正不断创造新体验,但歌唱语音合成领域(SVS,Singing Voice Synthesis)整体进展相对缓慢。
为拓展这一领域,近日,Soul App AI 团队(Soul AI Lab)联合吉利汽车研究院人工智能中心(AIC)、天津大学视听觉认知计算团队和西北工业大学音频语音与语言处理研究组(ASLP@NPU),正式开源歌声合成模型SoulX-Singer,这是一个面向真实应用场景设计的高质量零样本歌声合成模型,超42000小时训练数据,覆盖多语言、多音色及多种演唱风格,在稳定性、可控性与泛化能力方面,均达到了当前开源 SVS 模型中的领先水平。

SoulX-Singer介绍
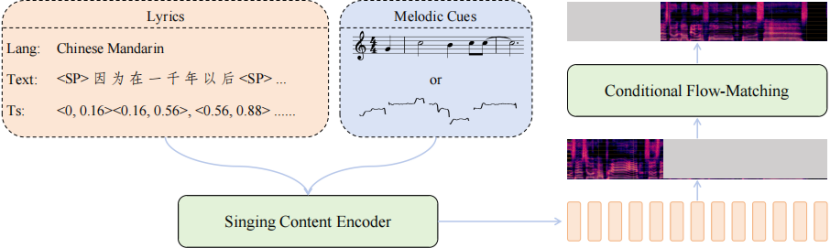
SoulX-Singer 结构简图
过去一段时间,语音合成与音乐生成领域迎来了快速发展,大模型与生成式 AI 持续刷新行业认知。然而,与这一热潮形成对比的是,行业内仍缺乏一个真正稳定可用、同时支持零样本(Zero-shot)生成的开源歌声合成(SVS)模型,这很大程度上制约了 SVS 技术在真实业务场景中的应用与落地。
SVS(Singing Voice Synthesis,歌唱语音合成)是一种根据歌词和乐谱生成歌声的技术。相比于普通语音合成(TTS,Text-to-Speech Synthesis),SVS 需要对音高、音律以及演唱风格等进行精细控制,以实现自然且富有表现力的歌声输出。与近期热门的 Music Generation(自动生成整段音乐或伴奏)不同,SVS 专注于可由 MIDI 控制的人声生成,因此在虚拟歌手、歌词演绎以及多语言歌声创作等场景中展现出独特价值。
在这样的背景下,SoulX-Singer 正式开源。SoulX-Singer 是一个面向真实工业应用场景设计的零样本歌声合成模型,其核心目标是在未见过歌手音色的情况下,实现稳定、自然且高度可控的歌声生成。为此,模型在整体架构、建模范式以及控制机制上进行了针对 SVS 场景的系统性设计。
在模型架构上,SoulX-Singer 采用基于Flow Matching 的生成建模范式,并将歌声合成问题建模为一种 audio infilling(音频补全)任务。针对歌声合成中“歌词—旋律—发声”三者强耦合的特点,SoulX-Singer 在建模阶段显式引入了note 级别的对齐机制。
模型通过构建歌词、MIDI 音符(note)与声学特征之间的精细对齐关系,使得每一个音符的起止时间、音高(pitch)以及持续时长都能够被准确建模和独立控制。这一设计使得模型不仅能够忠实还原乐谱信息,还可以在生成阶段灵活调整音符结构,从而满足音乐编辑、重编曲等复杂需求。
大规模 SVS 训练数据,夯实零样本能力基础
零样本歌声合成对训练数据的规模、多样性与覆盖范围提出了极高要求。SoulX-Singer 得益于超过 42000 小时的高质量歌声数据进行训练,覆盖多语言、多音色及多种演唱风格。
在如此大规模数据的支持下,模型在面对未见过的歌手与复杂音乐条件时,依然能够保持稳定、自然且高质量的合成表现。在实际测试中,SoulX-Singer 展现出了良好的鲁棒性和一致性,为零样本歌声合成技术从“可演示”走向“可使用”提供了坚实基础。
Music Score 与 Melody 多种控制方式
在生成控制能力方面,SoulX-Singer同时支持基于Music Score(MIDI)和基于 Melody的两种歌声合成控制方式:
·Music Score(MIDI)驱动生成支持直接基于乐谱与歌词生成歌声,适用于音乐创作、歌词编辑、歌曲重制等场景,具备音符级别的时长与节奏控制能力。
·Melody驱动生成支持从已有歌曲旋律出发进行歌声合成,可复刻参考音频中的演唱技巧与表达方式,适用于翻唱、风格迁移等应用场景。
这种双控制范式为实际音乐制作流程提供了更高的灵活性,使SoulX-Singer能够覆盖从“从零创作”到“基于已有歌曲再创作”的多种使用需求。
多语言支持,面向真实应用场景
SoulX-Singer 当前支持普通话、英语和粤语三种语言的歌声合成,并在不同语言和音乐风格下均展现出稳定一致的合成质量。这一多语言能力为其在内容创作、虚拟歌手、互动娱乐等应用场景中的落地提供了更广阔的空间。
客观表现
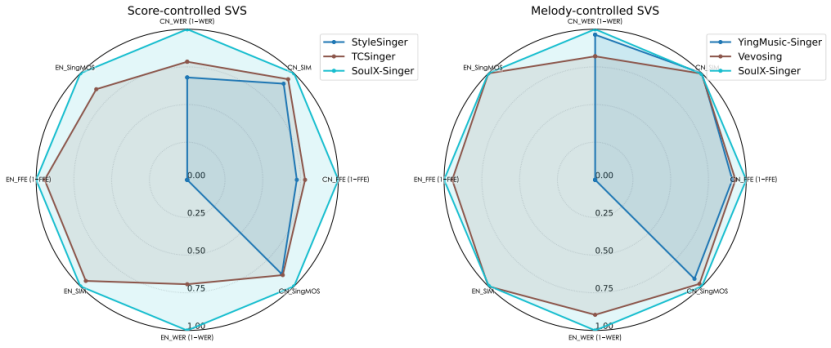
在评测方面,SoulX-Singer 在GMO-SVS和SoulX-Singer-Eval两个数据集上,对零样本歌声合成、歌词编辑后的歌声合成以及跨语言歌声合成等多项任务进行了系统评测。
其中,GMO-SVS 综合了GTSinger、M4Singer 和 Opencpop等主流开源 SVS 数据集;而 SoulX-Singer-Eval 则专门面向严格的零样本场景构建,通过独立音乐人等渠道采集数据,确保测试歌手未出现在训练集中。
实验结果表明,SoulX-Singer 在语义清晰度、歌手相似度、基频一致性以及整体合成质量等多个维度上均显著优于此前的相关工作;在主观听感评测中,其表现同样取得了明显领先优势。
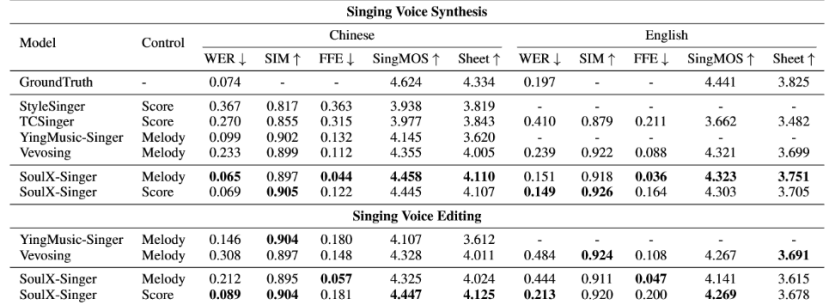
尽管此前歌声合成领域已经涌现出一些优秀的研究工作,但受限于训练数据规模或控制方式单一等因素,相关模型在真实使用场景中仍面临诸多挑战。SoulX-Singer 的发布提供了一个真正鲁棒、灵活可控且面向场景落地的零样本歌声合成解决方案,为歌声合成技术在UGC音乐创作等方向的实际应用探索带来了积极意义。
SoulX-Singer 也延续了Soul AI团队的开源工作。此前,Soul AI团队已陆续开源了播客语音合成模型SoulX-Podcast、实时数字人生成模型SoulX-FlashTalk,在语音、歌声、实时数字人、视频等不同领域提供了可落地的多模态生成方案。