2026-02-09 15:45:20 中华网
本文聚焦开源本地 AI 助手 OpenClaw,介绍其本地化部署、高权限等核心特性与快速走红的发展历程,凸显其资产数量的爆发式增长。重点剖析其存在的认证缺陷、漏洞、插件审核缺失等安全问题。结合 ZoomEye 资产测绘数据与创宇智脑 IP 情报数据综合研判发现,自 1 月 25 日 OpenClaw 关注度显著上升以来,全球范围内部分部署 OpenClaw 的 IP 对外发起攻击的频次出现异常增长,呈现出明显的异常活跃特征,疑似存在被恶意控制或滥用的风险迹象。最后给出防止 AI 智能体失控的措施,如更新版本、审核插件等,并阐述借助创宇盾的 Web 安全防护、协同防御等防护功能抵御相关攻击的方案。
OpenClaw是什么
OpenClaw (曾用名ClawdBot、Moltbot)是一款由 Peter Steinberger(PSPDFKit 创始人)开发的开源本地 AI 助手。与仅依赖云端服务器的商业化 SaaS 产品不同,OpenClaw 主要强调本地化部署和用户数据完全掌控,允许用户通过 WhatsApp、Telegram、Discord、飞书等日常聊天工具与其交互,并让它代替用户完成邮件处理、日程安排、代码编写、网页操作等一系列任务。
为了充分的调用插件工具、更好的提供服务,OpenClaw 具有极高的权限,可以执行任意本地命令。不同于被困在浏览器标签页的传统 AI,OpenClaw 使得 AI 可以自由的访问各类资源。这也意味着,如果用户在使用过程中缺少必要的监督,AI 甚至能格式化用户的电脑,并替用户给公司发送离职报告。
OpenClaw的快速走红
OpenClaw 的迅速走红并非偶然,其发展历程清晰展现了 AI 智能体技术从个人原型到社区级基础设施的演进路径。
2025 年 11 月,开发者 Peter Steinberger 在周末用不到一小时搭建了初始项目 “WhatsApp Relay”,完成了最早的概念验证(PoC)。该阶段项目仍停留在实验性质,但已经展示出“任务转发 + 自动执行”的智能体雏形。
2025 年 12 月,项目完成了核心架构 Gateway 的搭建,实现了更清晰的任务调度与执行分层。Steinberger 随后在个人博客中宣布 Agent 项目取得关键性突破,这一阶段标志着项目从简单脚本向可扩展智能体框架转型。
2026 年 1 月 5 日,项目在 GitHub 上正式更名为 ClawdBot(中文译名“龙虾”),并开始以完整 AI Agent 框架的形态对外发布,逐步吸引开发者关注。
2026 年 1 月 25 日,官方仓库 Star 数量在短时间内暴涨,OpenClaw(当时仍为 ClawdBot)迅速在开发者社区和安全研究圈走红,被视为“低门槛构建 AI 智能体”的代表性项目之一。
2026 年 1 月 27 日,项目因命名问题被 Anthropic 指控侵权,被迫更名为 Moltbot。尽管遭遇争议,但这一事件反而进一步提升了项目的曝光度。
2026 年 1 月 28 日,全球首个 AI 智能体社区 Moltbook 正式上线,围绕智能体模板、任务编排和工具链展开协作,项目开始呈现出明显的生态化趋势。
2026 年 1 月 30 日,项目最终定名为 OpenClaw,名称融合了“开源(Open)”与“智能体开口执行任务(Claw)”的双重含义,标志着其正式以开源 AI 智能体平台的身份进入快速发展阶段。
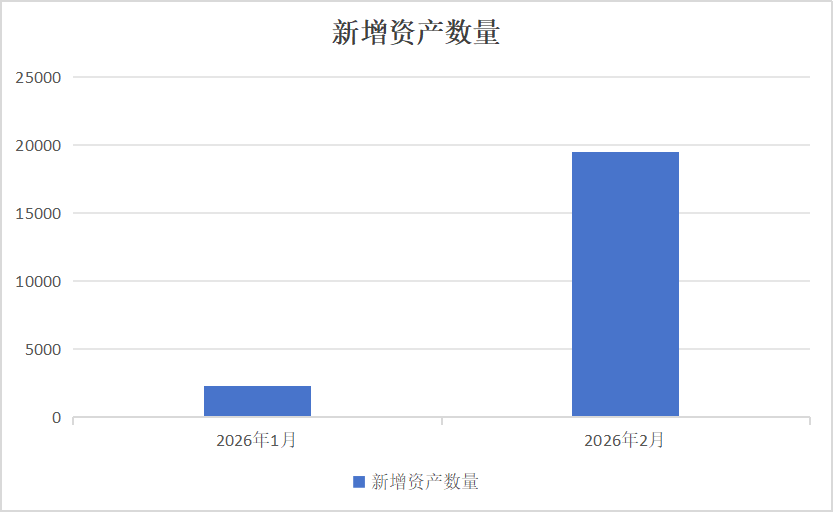
OpenClaw 目前有多火呢?我们借助 ZoomEye 平台的测绘数据可见一斑,其新增资产数量从 2026 年 1 月的不足 3000,到 2026 年 2 月的高达 19000+。
OpenClaw的安全问题
随着 OpenClaw 在开发者社区中的迅速走红,其代码库也同步成为全球安全研究人员重点审计和分析的对象。大量研究成果在短时间内集中披露,尽管相关漏洞在被报告后大多得到了官方的快速响应与修复,但高危安全问题的密集暴露仍使 OpenClaw 在其发展早期便长期处于安全争议的中心。
在已披露的安全事件中,多个问题直接影响核心安全边界,具体包括:
2025 年 11 月:项目初始版本引入了 Gateway 认证逻辑缺陷,攻击者可在特定条件下绕过身份验证机制获取访问权限。该问题自项目创建之初即存在,直至 2026 年 1 月 29 日 才完成修复,暴露时间跨度较长。
2026 年 1 月 26 日:安全研究员 Henrique Branquinho 披露漏洞 CVE-2026-25253。攻击者可通过构造恶意 URL 并诱导受害者访问,从而窃取其 Gateway 令牌,进而控制智能体实例。官方于 1 月 29 日发布补丁进行紧急修复。
2026 年 1 月 27 日:OpenClaw 曾用名 Moltbot 的 npm 包遭恶意抢注。若用户按照过时文档继续安装相关依赖,将面临代码投毒与供应链攻击风险。截至目前,该问题仍未得到彻底解决。
2026 年 1 月:安全研究员 koko9xxx 与 Berk Dedekargınoğlu 分别披露 CVE-2026-25157(远程命令执行)与 CVE-2026-24763(命令注入)漏洞,并于 1 月 29 日完成修复。
除上述已编号漏洞外,OpenClaw 生态中仍存在多项尚未完全解决的结构性安全风险:
一方面,官方 skill 插件仓库缺乏完善的审核与签名机制,导致攻击者曾成功向官方存储库上传携带恶意逻辑的 skill 插件,形成潜在的供应链攻击入口。
另一方面,OpenClaw 缺乏针对提示词注入(Prompt Injection)的系统性防护机制,攻击者可通过邮件、网页内容等外部输入触发间接提示词注入,从而影响智能体的决策与执行行为。
疑似失陷的OpenClaw
借助 ZoomEye 测绘平台与知道创宇安全智脑平台,我们将部署了 OpenClaw 的 IP 与知道创宇安全智脑平台捕获的 IP 进行交叉分析,得到了一批有明显攻击行为的异常 IP。
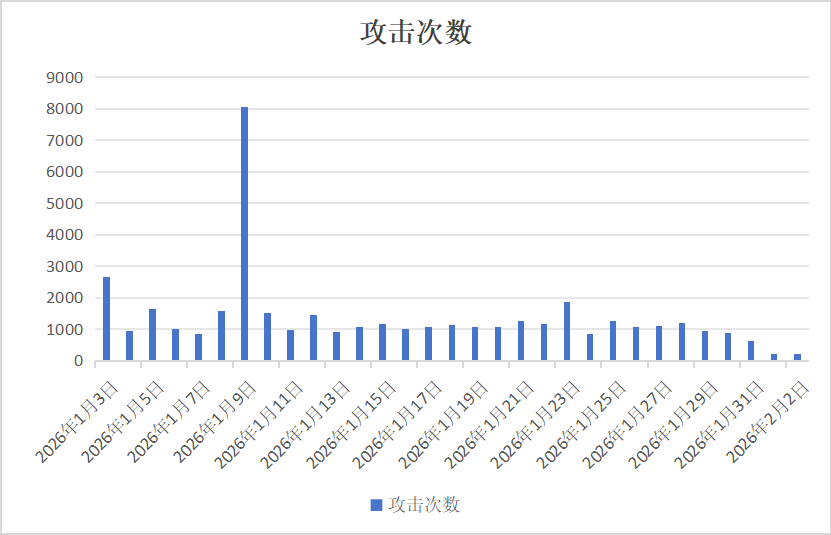
在 2026-01-03 至 2026-02-02 的近一个月统计周期内,这批异常 IP 的攻击情况总览如下。
我们对该批异常 IP 的攻击类型进行了聚合分析,结果如下:
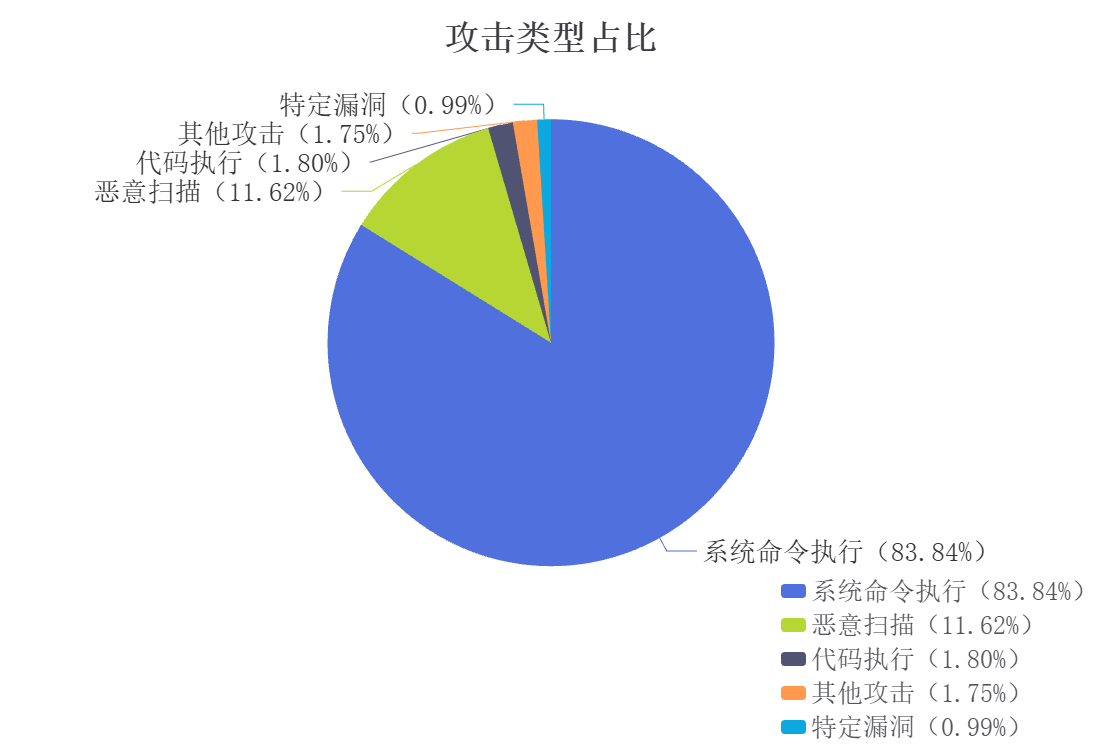
其攻击类型主要是系统命令执行和恶意扫描,整体行为呈现出高度自动化特征,与OpenClaw AI 智能体驱动的自动化扫描工具行为特征相吻合。
对被攻击目标进行聚合,被攻击目标 TOP 5 如下:
被攻击目标聚合统计结果
被攻击目标数量占比
d**t.a**i.c**x.gov.cn5,14210.63%
a**y.a**g.gov.cn3,9708.21%
g**y.b**u.gov.cn3,0986.40%
w**w.y**u.gov.cn2,3724.90%
t**s.a**i.c**x.gov.cn2,1794.50%
发现被攻击的目标主要集中在政务、公共信息服务等领域。
同时,我们发现自 OpenClaw 在 1 月 25 日关注度激增后,这批异常 IP 中的部分 IP攻击次数出现显著增长,存在被控制的可疑迹象。
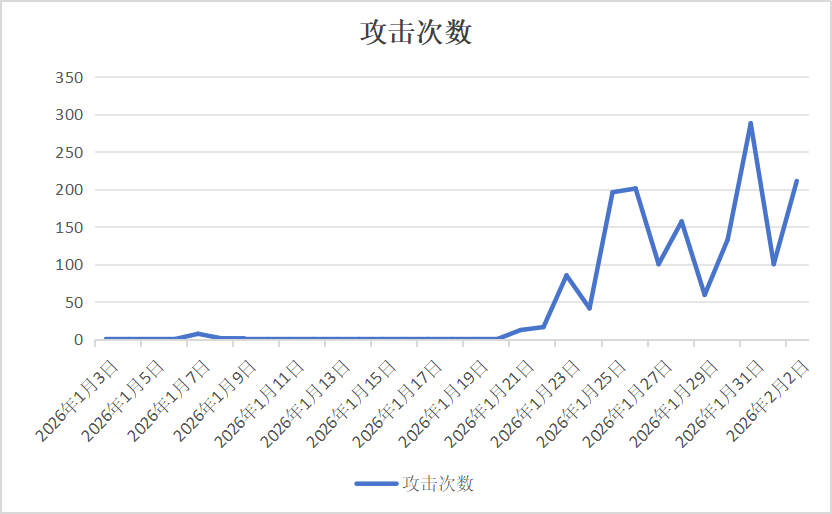
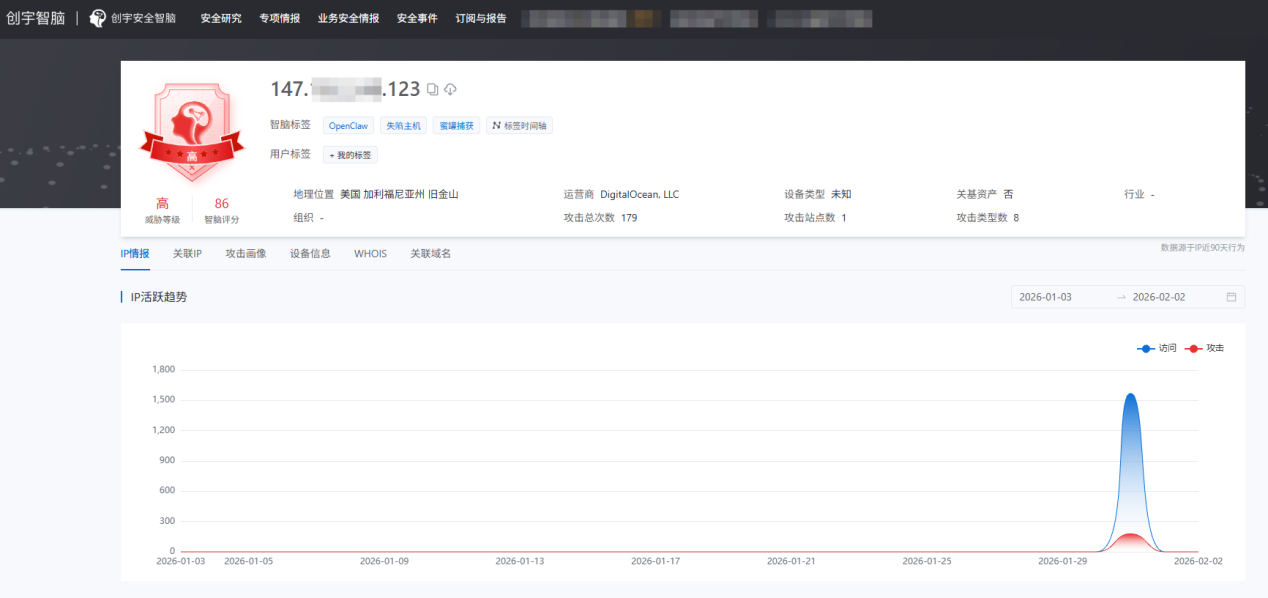
如何防止AI智能体失控
AI 智能体与传统 AI 应用的本质区别,在于其具备自主、持续执行任务的能力。这一特性在显著提升自动化效率的同时,也改变了风险的传导路径:安全风险不再仅来源于程序代码本身的漏洞,更可能源于大模型对指令、上下文或外部输入的语义误判,并在无人干预的情况下被持续放大和执行。
在 OpenClaw 智能体平台的安全问题中可以看到,一旦攻击者能够影响智能体的输入、执行逻辑或插件生态,便有可能实现从“诱导模型理解”到“控制实际执行”的完整攻击链。因此,防止 AI 智能体失控,本质上是对“模型决策能力 + 执行权限”的双重约束。
结合当前已暴露的风险形态,可采取以下措施降低 OpenClaw等 AI 智能体被劫持或滥用的风险:
1. 保持版本及时更新
升级至 v2026.2.3 或更高版本,确保已修复已知的身份认证、命令执行及注入类漏洞,避免因历史安全缺陷被自动化攻击批量利用。
2. 谨慎对待插件与生态依赖
避免盲目信任官方或第三方仓库中的 skill 插件。在安装前应进行代码审计,重点关注是否存在隐蔽命令执行、外部通信或权限滥用逻辑,防范供应链投毒风险。
3. 收紧执行权限,建立“人类在环”机制
关闭或限制高危场景下的自动执行能力,对智能体的关键操作(如系统命令、文件写入、网络请求)引入人工确认或策略校验,防止模型误判导致不可逆操作。
如何防御来自失控AI智能体的攻击
失控的 AI 智能体并不等同于传统意义上的“脚本小子”或单点攻击者,其攻击行为往往呈现出高频自动化、快速迭代、跨目标复用策略等特征。一旦智能体被恶意操控或被提示词诱导,其攻击能力将被持续放大,形成类似“攻击自动化工厂”的效果。
在这一背景下,防御重点不再只是拦截某一次攻击请求,而是阻断智能体规模化执行、情报复用与持续试探的能力。以创宇盾为代表的AI+大模型驱动的下一代智能云防御平台,在应对这类新型威胁中具备天然优势。
1. 以 Web 安全基础防护阻断“智能体执行链”
失控 AI 智能体最常见的攻击入口,仍然是 Web 层面的通用漏洞,如命令执行、SQL 注入、文件包含、接口探测等。
创宇盾基于全球海量风险样本库和持续攻防对抗能力,能够在 2 小时内快速应对 N-day / 0-day 漏洞攻击,有效阻断智能体将“模型决策”转化为“真实执行”的第一步。
2. 利用协同防御机制压制规模化智能体攻击 AI 智能体攻击的核心优势在于“可复制性”:一旦某种攻击策略或目标验证成功,便会被迅速复用于其他目标。
创宇盾通过协同防御机制与创宇安全智脑实时共享全网安全情报,实现“一网发现、全网拦截”。当某一节点识别出异常 AI 智能体攻击行为后,相关 IP、特征及模式会被快速同步至全网,从而在攻击扩散前完成整体压制。
3. 通过拟态防御干扰智能体的决策反馈
与人类攻击者不同,AI 智能体高度依赖“请求—响应—评估”的反馈闭环来调整攻击策略。创宇盾的拟态防御技术能够对外部请求返回不符合预期的响应结果,从而:干扰模型对漏洞是否存在的判断、误导智能体对攻击效果的评估、显著提高其攻击成本与决策不确定性。
对于依赖反馈不断优化策略的 AI 智能体而言,这种“不可预测性”往往比直接封堵更具破坏性。