2025-12-31 11:42:02 西盟科技资讯
YuanLab.ai团队正式开源发布源Yuan3.0 Flash多模态基础大模型。Yuan3.0 Flash是一款40B参数规模的多模态基础大模型,采用稀疏混合专家(MoE)架构,单次推理仅激活约3.7B参数。Yuan3.0 Flash创新性地提出和采用了强化学习训练方法(RAPO),通过反思抑制奖励机制(RIRM),从训练层面引导模型减少无效反思,在提升推理准确性的同时,大幅压缩了推理过程的token消耗,显著降低算力成本,在“更少算力、更高智能”的大模型优化路径上更进一步。
Yuan3.0 Flash 由视觉编码器、语言主干网络以及多模态对齐模块组成。语言主干网络采用局部过滤增强的Attention结构(LFA)和混合专家(MoE)结构,在提升注意力精度的同时,显著降低训练与推理的算力开销。多模态方面,采用视觉编码器,将视觉信号转化为token,与语言token一起输入到语言主干网络,通过多模态对齐模块实现高效、稳定的跨模态特征对齐。同时,引入自适应图像分割机制,在支持高分辨率图像理解的同时,有效降低显存需求及算力开销(如图1)。
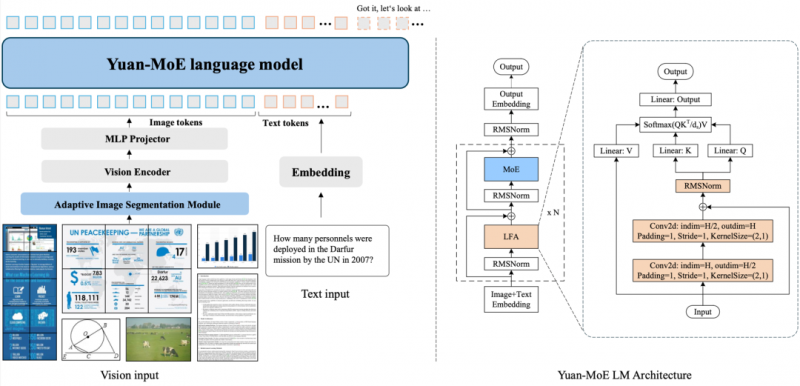
图1:Yuan 3.0整体架构和基于MoE的语言主干。左侧为Yuan 3.0架构,含三个组件:(1) ViT编码器处理图像;(2) 轻量级MLP投影器对齐视觉与文本特征;(3) 基于MoE的语言模型。右侧为采用局部过滤注意力(LFA) 的源3.0语言主干网络。
更值得关注的是,在企业场景的 RAG(ChatRAG)、多模态检索(Docmatix)、多模态表格理解(MMTab)、摘要生成(SummEval)等任务中, Yuan3.0 Flash 的表现已优于 GPT-5.1,体现出其在企业应用场景中的明显能力优势。在多模态推理与语言推理评测中,Yuan3.0 Flash(40B)精度接近Qwen3-VL235B-A22B(235B)与DeepSeek-R1-0528(671B),但 token 消耗仅约为其 1/4 ~ 1/2,显著降低了企业大模型应用成本(如图2)。
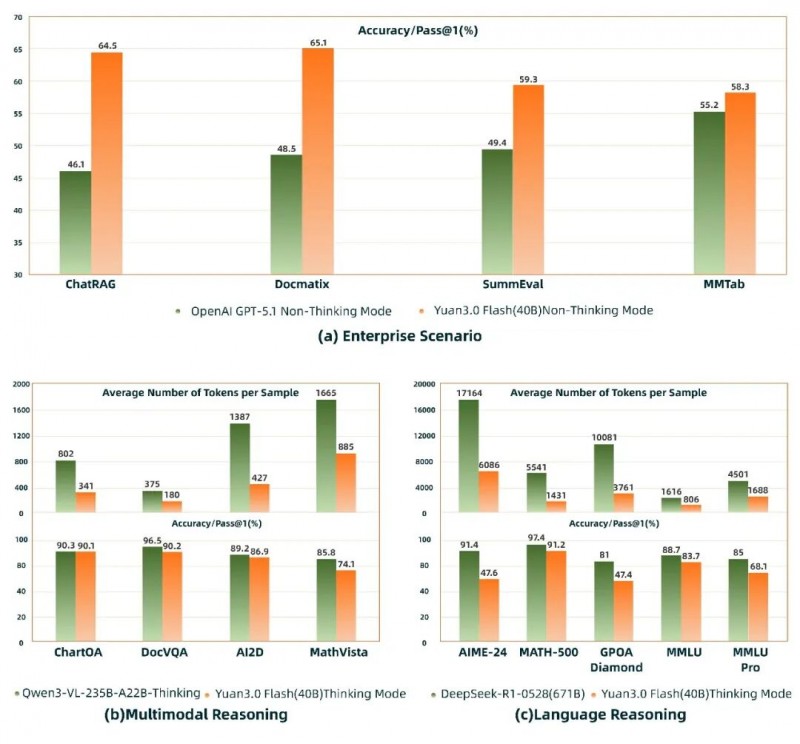
图2:Yuan3.0 Flash在企业级、多模态和语言模态上的基准测试表现
Yuan3.0 Flash 全面开源,全系列模型参数和代码均可免费下载使用:
https://github.com/Yuan-lab-LLM/Yuan3.0
不追求“更长思考”,而是“更有效思考”
近年来,长思维链(Chain-of-Thought)成为提升大模型推理能力的主流范式,但在实际应用中也带来了新的问题:推理过程冗长、算力消耗大、部署成本高,甚至在得到正确答案后仍持续大量生成冗长的内容,(如图3)。
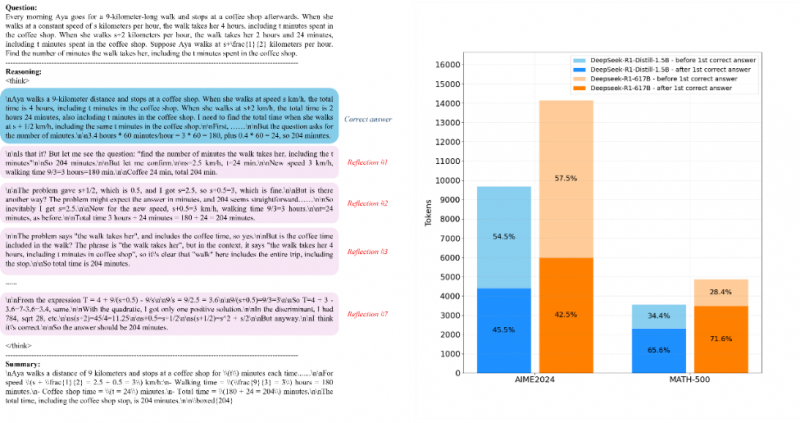
图3: Deepseek-R1的重复反思行为示例
针对推理模型普遍存在的 “过度思考(Overthinking)”问题,Yuan3.0 Flash 创新Reflection-aware Adaptive Policy Optimization(RAPO) 强化学习算法,提出反思抑制奖励机制(RIRM),从训练层面引导模型减少无效反思,专注于必要推理步骤(如图4)。
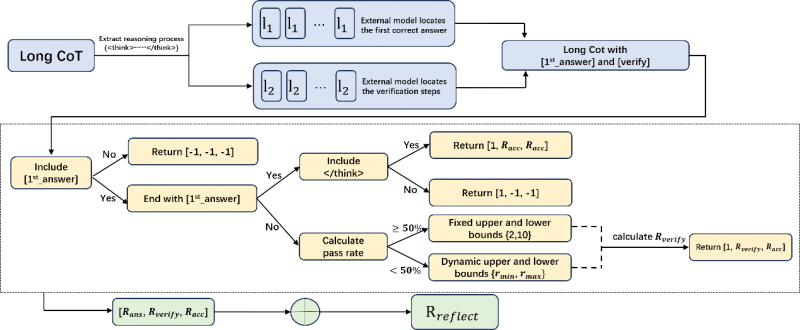
图4:反思抑制奖励机制(RIRM)
该机制能够识别模型首次得到正确答案的关键节点,并对后续冗余推理行为进行抑制,使模型在保证答案正确性的前提下,大幅压缩输出长度。实验结果表明,在数学、科学与复杂推理任务中,Yuan3.0 Flash 在准确率提升的同时,推理 token 数量最高可减少约 75%,显著降低推理成本。
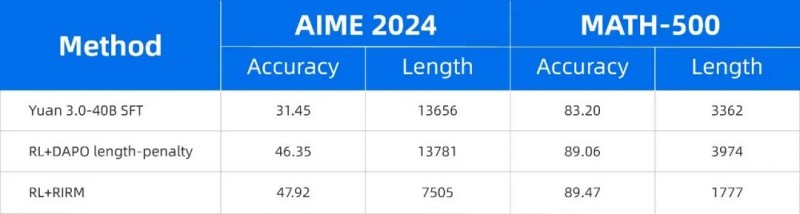
表1:Yuan3.0 Flash采用RIRM的强化学习训练与DAPO+长度惩罚的精度与输出token数量对比
在 RAPO 框架下,模型同时支持深度推理任务与快速推理任务的统一训练,并通过:
自适应动态采样(ADS)
高熵 Token 选择的 80/20 训练策略
优化的双重裁剪机制
长短输出分组交替训练
在大规模 MoE 模型上实现了更稳定的强化学习训练,训练效率提升52.91%。Yuan3.0 Flash能够在默认推理模式下即可满足绝大多数企业场景需求,而无需额外开启“深度思考模式”,真正实现“默认即高效、即智能”。
企业场景下模型能力的提升,离不开高质量数据支撑
Yuan3.0 Flash的优秀表现,并非仅依赖算法本身,而是建立在面向企业真实场景的数据准备工作之上。与通用对话或互联网语料不同,模型在训练阶段重点引入了大量贴近企业生产环境的数据形态,包括:
长篇技术文档、解决方案材料、操作手册、投标文件等复杂文本
财务与业务报表、多级表头表格、嵌套表格与图文混排页面
跨页面、多模态信息联合理解的真实业务场景
围绕这些输入形态,训练数据重点覆盖多模态信息检索、对比分析、摘要生成、表格分析与理解等企业高频任务。同时,在数据构建阶段,团队显式区分了无需深度推理即可完成的任务与确需多步推理的复杂任务,为后续强化学习阶段优化推理效率提供了明确的数据基础。
面向企业场景的多模态基础能力
在能力层面,Yuan3.0 Flash 并非围绕单一 Benchmark 优化,而是针对企业真实业务需求进行了系统设计。在多项企业级评测中,模型在以下能力上表现突出:
检索增强生成(RAG):在 ChatRAG、DocMatix 等评测中取得领先成绩
复杂表格与文档理解:在 MMTab 等多任务基准中展现领先能力
高质量总结生成:在 SummEval 上兼顾语义一致性与事实准确性
多模态推理效率:在 ChartQA、DocVQA 等任务中,以更少token 达到比肩前沿大模型的精度
结合对128K长上下文的稳定支持,Yuan3.0 Flash 能够胜任企业级长文档分析、跨页面信息检索与多源知识融合任务(如图5)。
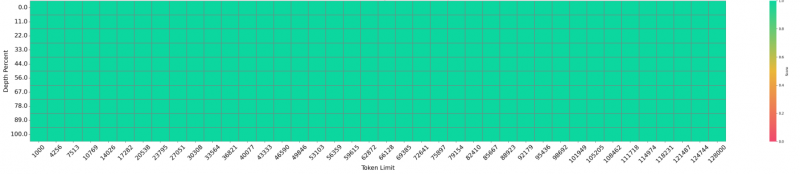
图5: Yuan3.0 Flash在"大海捞针"测试中实现100%精度召回
开源基础模型,推动可落地的大模型智能
Yuan3.0 Flash大模型全面开源,不仅包括模型权重(16bit与4bit模型)、技术报告,也涵盖完整的训练方法与评测结果,支持社区在此基础上进行二次训练与行业定制。YuanLab.ai团队希望通过这一开源基础模型,推动大模型从“能力展示”走向“规模化落地”,为企业提供 可控成本、可预测性能、可持续演进 的多模态智能底座。
“更少算力,并不意味着更弱能力;更高智能,也不一定依赖更大模型。”Yuan3.0 Flash 正是在这一理念下,对下一代基础大模型形态的一次探索与实践。
源Yuan 3.0基础大模型将包含Flash、Pro和Ultra等版本,模型参数量为40B、200B和1T等,我们将陆续发布相关工作。
「开源地址」
代码开源链接
https://github.com/Yuan-lab-LLM/Yuan3.0
论文链接
https://github.com/Yuan-lab-LLM/Yuan3.0/blob/main/docs/YUAN3.0_FLASH-paper.pdf
模型下载链接1)Huggingface:
https://huggingface.co/YuanLabAI/Yuan3.0-Flash
https://huggingface.co/YuanLabAI/Yuan3.0-Flash-4bit
2)ModelScope:https://modelscope.cn/models/Yuanlab/Yuan3.0-Flash
https://modelscope.cn/models/Yuanlab/Yuan3.0-Flash-int4