2025-06-12 17:36:48 中华网
传统的分析系统在面对海量数据和高并发查询时,往往难以满足严苛的实时性要求。延迟,哪怕是秒级的,也可能导致商业机会的错失或用户体验的下降。StarRocks 的设计初衷便是为了攻克这些难题,它通过一系列创新的技术架构和优化手段,为用户提供了极致的查询性能。
要理解 StarRocks 为何能快,就必须深入其内核,探究其背后的技术支柱。向量化执行引擎、CBO 优化器和列式存储——这三大核心技术如同三驾马车,共同驱动着 StarRocks 驶向实时分析的快车道。
核心技术一:向量化执行引擎——释放 CPU 的极致潜能
在传统的数据库查询执行模型中,数据通常是逐行(Tuple-at-a-time)处理的。这意味着 CPU 在处理每一行数据时,都需要进行一次函数调用和相应的上下文切换,当数据量巨大时,这种开销会显著累积,成为性能瓶颈。

向量化执行引擎的性能优势
向量化执行引擎(Vectorized Query Engine)采用了截然不同的策略。它不再逐行处理数据,而是将一批数据作为一个单元进行处理。这意味着对一批数据应用某个操作(如过滤、计算)时,CPU 可以执行一条指令处理多个数据项(SIMD - Single Instruction, Multiple Data),或者通过循环一次性处理整个数据批次。
StarRocks 从一开始就将向量化执行作为其核心设计理念之一。其查询引擎的各个层面,从数据扫描、表达式计算、聚合、排序到 Join 操作,都深度融入了向量化思想。
数据扫描与过滤:在读取数据时,StarRocks 直接以列式批处理的方式获取数据,并在这些数据批次上执行过滤条件,高效剔除不符合条件的数据。
表达式计算:复杂的 SQL 表达式被分解为一系列针对数据批次的操作,例如,a + b * c 这样的计算会在整个数据批次上统一执行。
聚合函数优化:SUM, COUNT, AVG, MAX, MIN 等聚合函数在向量化引擎中能够高效处理整批数据,快速得到聚合结果。StarRocks 的技术内幕文档中也提到了其标量函数与聚合函数的实现细节。
StarRocks 的向量化编程精髓在于其对 CPU 底层特性的深刻理解和极致运用。通过精心设计的内存布局、算法选择以及对 SIMD 指令的充分利用,StarRocks 的向量化引擎为毫秒级查询奠定了坚实的基础。
核心技术二:CBO 优化器——智能规划最佳查询路径
对于复杂的分析查询,尤其是涉及多表关联、子查询和复杂谓词的场景,可能存在成千上万种执行计划。选择一个低效的计划可能导致查询耗时指数级增加。CBO 的职责就是从众多可能的执行计划中,基于成本估算模型,智能地选择一个最优或接近最优的执行计划。

StarRocks 的 CBO 优化器关键特性包括:
1. 完善的统计信息收集与利用
StarRocks 3.2 版本开始支持收集外部表(包括 Hive 与 Iceberg)的统计信息,3.3 版本进一步支持了直方图统计信息,并且增加了对复杂类型 Struct 子列的统计信息收集 。
2. 智能的查询改写
CBO 能够进行复杂的查询改写,例如谓词下推、子查询展开、公共表达式提取等,将原始 SQL 转化为更易于高效执行的形式。
对于查外部 Catalog,如果外部表引擎具备计算能力,StarRocks 的 CBO 会尝试将聚合计算(如 GROUP BY, LIMIT)尽可能推到外表引擎执行,从而减少网络传输的数据量 。
3. 物化视图的智能选择与改写
CBO 能够识别查询是否可以利用已有的物化视图,并自动改写查询以从物化视图中获取数据,从而避免对原始基表的昂贵计算。

StarRocks 的 CBO 能够在数万级别的执行计划搜索空间中,选择成本最低的最优执行计划 ,确保即便是复杂的分析请求也能获得高效的响应。
核心技术三:列式存储——为分析而生的存储结构
传统的行式存储(Row-based Storage)将一行中的所有列连续存储在一起,这对于事务处理(OLTP)场景非常友好,因为事务通常需要访问或修改一整行数据。然而,分析查询(OLAP)往往只关心表中的少数几列,但行式存储却需要将整行数据(包括不相关的列)都读入内存,造成大量的 I/O 浪费和 CPU 处理开销。
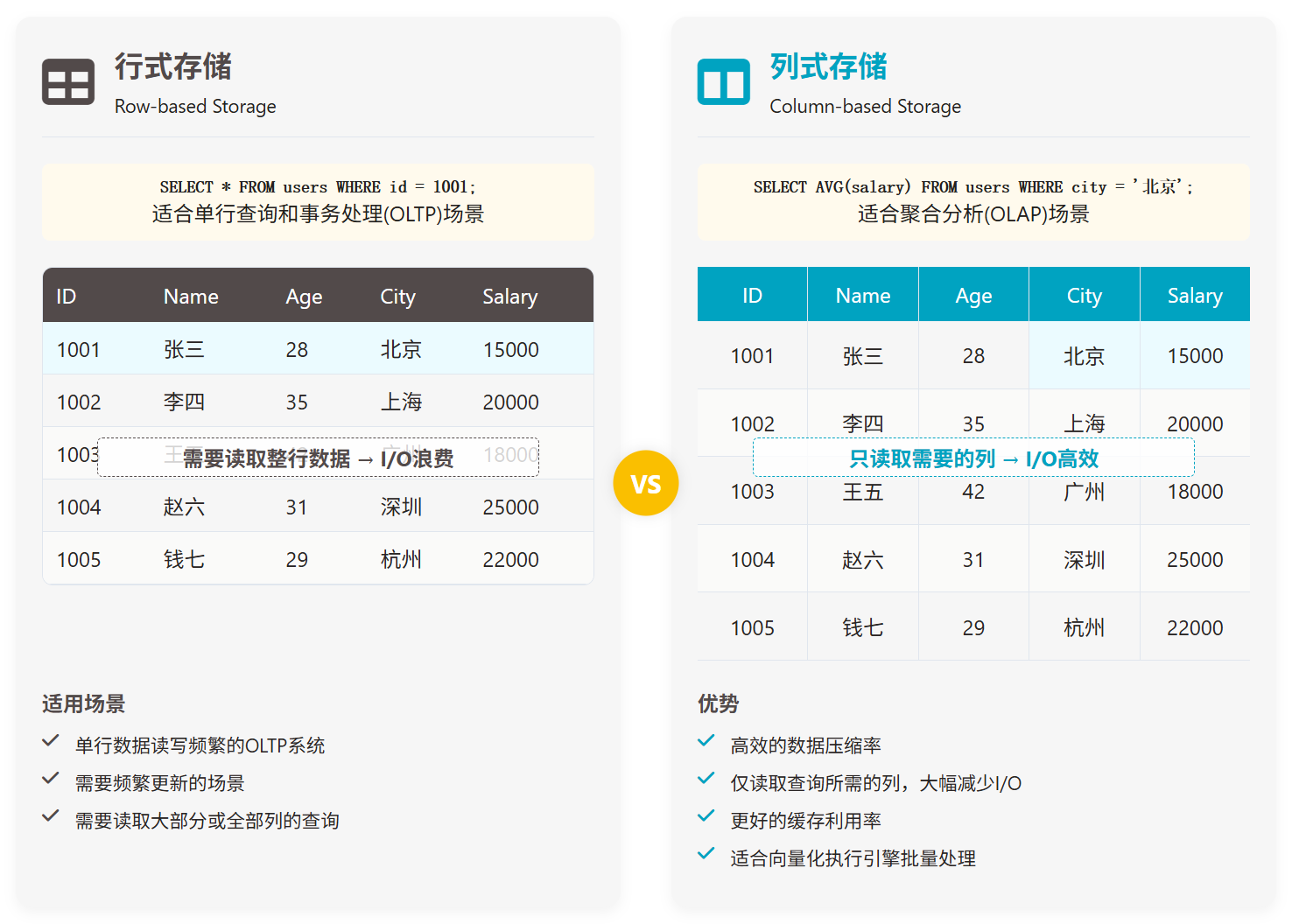
StarRocks 从底层设计就采用了列式存储。其存储引擎不仅实现了高效的列式数据读写,还结合了多种优化技术来进一步放大列式存储的优势:
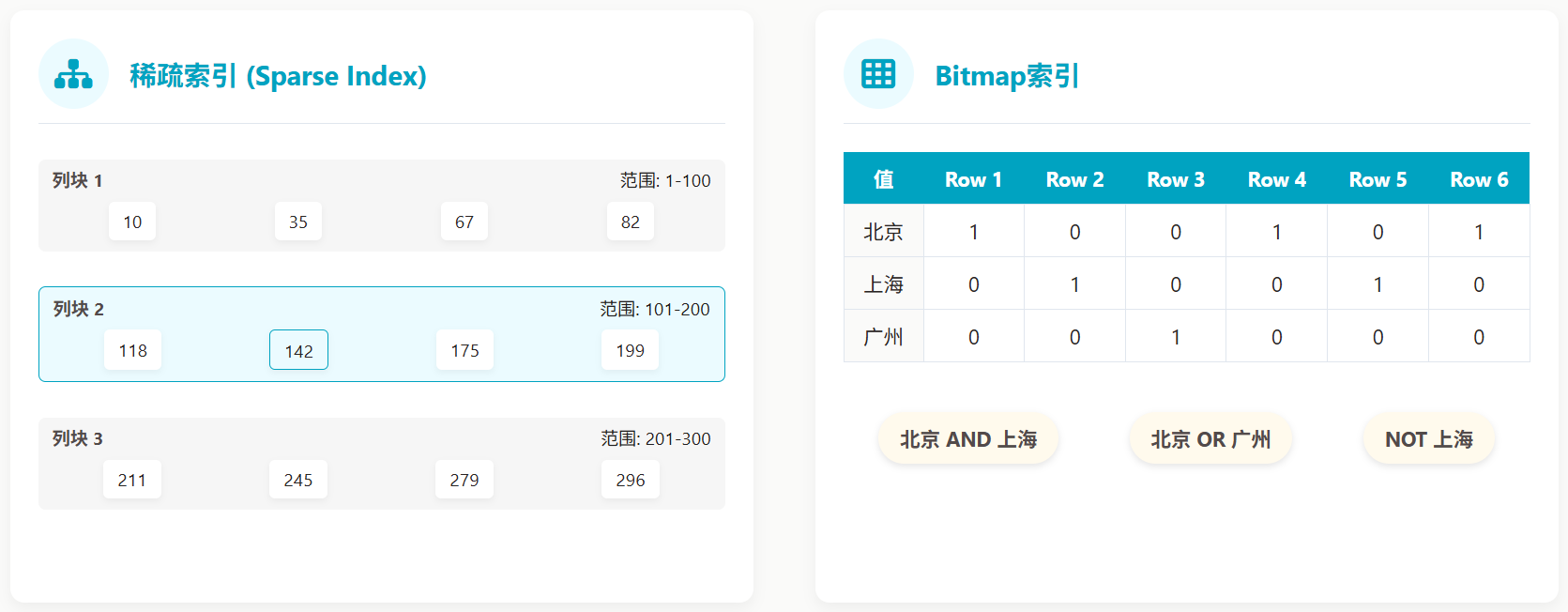
1. 智能索引:
稀疏索引(Sparse Index):StarRocks 为每个列块(Column Block)自动创建稀疏索引,能够快速定位到包含目标数据的列块,避免全列扫描。
Bitmap 索引:对于低基数列(如性别、地区),Bitmap 索引能够高效地执行 AND、OR、NOT 等逻辑运算,加速复杂条件的过滤。
2. 灵活的数据模型:StarRocks 支持明细模型、聚合模型和主键模型。

3. 分区与分桶:
分区(Partitioning):逻辑上将表划分为多个分区,通常按时间维度分区,查询时可以只扫描相关的分区,大幅减少数据扫描量。
分桶(Bucketing):将数据通过哈希方式分散到不同的 Tablet 中,Tablet 是数据均衡和副本管理的基本单位。合理的分桶策略有助于查询并发和负载均衡。

列式存储是 StarRocks 实现高性能分析的基础。它与向量化执行引擎、CBO 优化器紧密配合,共同构成了 StarRocks 强大的分析能力。
企业级实践
企业在实际生产环境中,除了极致性能,还需要更完善的企业级特性、金融级的安全保障、便捷的运维管理以及对国产化生态的兼容。镜舟科技作为全球领先开源项目 StarRocks 的主要贡献者,基于技术积累和对行业的深刻洞察,推出了企业级产品——镜舟数据库 。镜舟数据库在继承 StarRocks 核心优势的基础上,进行了企业级优化和功能增强。
更完善的企业级功能特性
镜舟数据库针对企业复杂应用场景,提供了更为丰富和成熟的功能:
Multi-warehouse(多虚拟数仓):业内领先的简化架构设计,允许企业根据不同部门、地域或业务集群的需求,建立多个逻辑上隔离的虚拟子数仓。这既避免了物理集群林立导致的架构臃肿,又能为每个需求分支提供隔离的计算资源,大幅提升使用性能和管理灵活性。StarRocks 的资源隔离原理解析也体现了其对多租户和资源划分的思考。
RBAC(Role-Based Access Control,基于角色的访问控制):提供精细化的权限管理体系,确保数据访问的安全合规。
可视化 SQL 编辑器:内置易用的 SQL 开发工具,提升数据分析和开发效率。
物化视图自动推荐:基于查询负载和数据特征,智能推荐创建物化视图,进一步加速查询。
总结
基于向量化执行引擎、CBO 优化器和列式存储这三大核心技术支撑的StarRocks,镜舟科技助力多家金融、零售、制造企业构建能够实现毫秒级实时分析的企业级数据平台。这些技术不仅解决了传统数据架构的性能瓶颈,还大幅降低了企业的建设成本和维护复杂度。
随着数据规模的持续增长和实时性要求的不断提升,镜舟科技将继续深化技术创新,在 AI 智能优化、多云部署等方向持续发力,为企业数字化转型提供更强大的数据分析能力支撑。